최근 프로젝트와 관련하여 벤치마킹할 논문을 정해서 읽어보게 되었습니다.
제목은 "What is in Your Password? Analyzing Memorable and Secure Passwords using a Tensor Decomposition"이며 2019년 The World Wide Web Conference에 publish 된 논문이며, 자세한 내용은 직접 읽어보는걸 추천합니다.
본 글에서는 간단히 논문의 대략적인 내용에 대해 정리합니다.
논문 링크 : https://dl.acm.org/doi/10.1145/3308558.3313690
What is in Your Password? Analyzing Memorable and Secure Passwords using a Tensor Decomposition | The World Wide Web Conference
Overall Acceptance Rate 1,087 of 7,181 submissions, 15%
dl.acm.org
논문의 전체적인 흐름을 간단히 살펴보면 아래와 같습니다.
과거 연구들은 패스워드의 구조와 패스워드의 견고함을 분석하는 연구가 주된 주제였다.
하지만, 어떤 패스워드가 기억하기 쉬우며 견고한 패스워드인지 이해하기 위한 많은 질문이 존재한다.
본 논문에서는 이러한 몇가지 질문에 답하기 위해 데이터 과학과 머신러닝의 관점에서 패스워드를 분석한다.
저자들은 패스워드 데이터셋을 구축하여 3가지의 그룹(Weak, Medium, Strong)으로 패스워드를 구분하였다.
그 다음으로 간단한 전처리 과정을 거친 뒤, PARAFAC2 tensor decomposition을 이용하여 데이터 분석을 진행하였다.
decomposition의 결과를 이용하여 저자들은 견고한 패스워드의 주된 특징들을 분석할 수 있었으며, 견고한 패스워드에 영향을 끼치는 요인들도 알 수 있었다.
제가 가장 관심 있게 읽은 부분은 데이터 수집과 분석 방법에 관한 부분이였습니다.
우선 데이터를 어떻게 수집하고 구성하였는지 정리하고, 정리된 데이터를 이용하여 어떤 기법으로 어떻게 분석하였으며,
분석 결과에 대한 논문에서 제시한 해석을 살펴보고자 합니다.
1. Data
데이터는 (Woo et al., Life-experience passwords(LEPs), ACSAC, 2016)에서 공개한 데이터셋을 활용하였으며, 3200개 이상의 패스워드로 구성되어 있는 데이터셋 입니다.
저자들은 패스워드의 기억력(패스워드를 얼마나 강하게 기억할 수 있는지)을 측정하기 위해 Monte Carlo method를 사용하였으며, 21만 개의 weak password를 이용하여 guessing algorithm을 학습하였습니다.
학습 결과 저자들은 3개의 그룹으로 데이터를 나눌 수 있었으며, 각 그룹별 데이터의 비율과 기준은 다음과 같습니다.
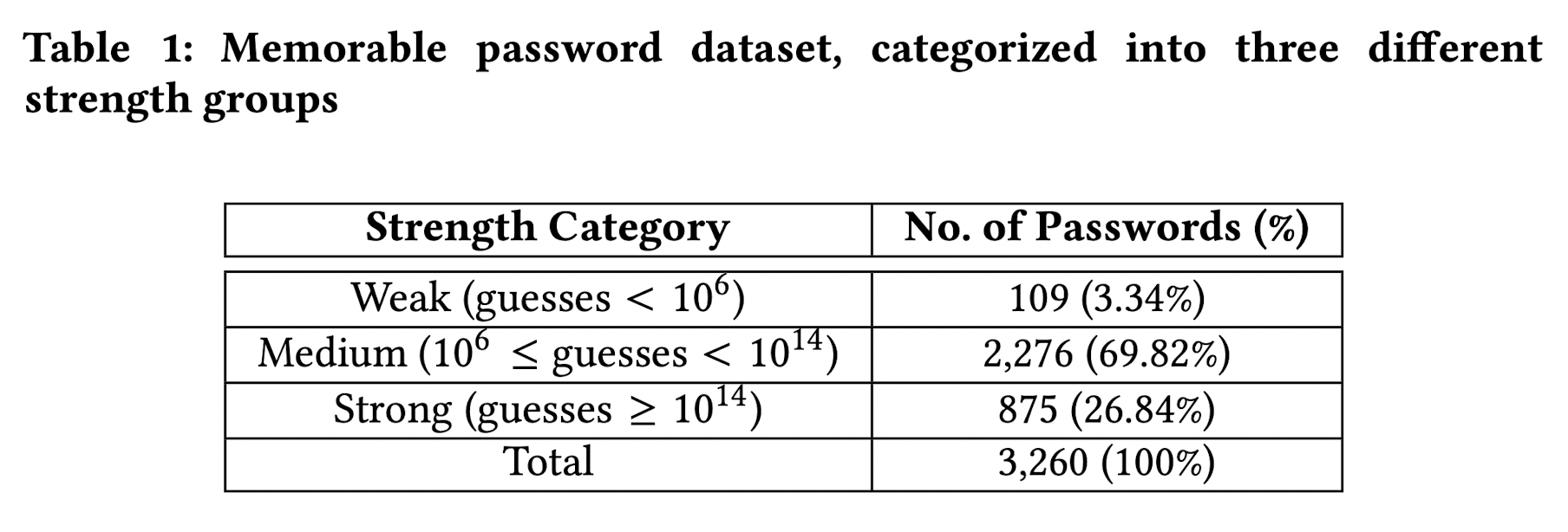
저자들은 3개의 그룹으로 분류 후에 패스워드의 특징을 만들었으며, 각 특징은 2가지 그룹으로 구성되어 있습니다.
첫번째 그룹은 syntactic feature이며, 두 번째 그룹은 semantic feature입니다.
syntactic feature 그룹은 다음과 같이 12개의 feature들로 구성되어 있으며, 각 label별 설명은 다음과 같습니다.
[Label : explanation]
1. length : length of password
2. D : the number of digits
3. S : special character
4. UL : upper case letter
5. 3class8 : digits, special character, uppercase and lowercase letter에 모두 해당하는 경우
6. tFlips : the total number of flips
7. flipLS : lowercase letter to special character
8. filpDL : lowercase letter to digit
9. flipDS : digits to special character
10. flipDL : digit to lowercase letter
11. flipSL : special character to lowercase
12. flipSD : special character to digit
다음으로 semantic feature group은 55개의 feature로 구성되어 있으며, (Vera et al., On the semantic patterns of passwords and their security impact, NDSS, 2014)의 semantic segmentation parser를 이용하였습니다. 해당 논문에서는 CLAWS7 tag set을 이용하였으며, 해당 tag set은 University Centre for Computer Corpus Research on Language (UCREL)에서 공개한 POS tagger를 사용했습니다.
저자들은 CLAWS7에 추가로 'specialn' 과 'charm' 태그를 추가하였으며, 최종적으로 총 114개의 서로 다른 semantic feature(tags)를 추출하였습니다.(후에 저자들이 중요하다고 생각하는 55개의 semantic feature를 선택한 것으로 생각됩니다.)
1.1 Preprocessing and Refinement
전처리는 크게 두 단계로 구성되어 있습니다.
첫 번째 단계는 Removeing near zero variance feature입니다.
분산이 작은 경우, 통계 분석에 악영향을 끼칠 수 있기 때문에 제거해주는게 좋습니다. 또한 다르게 생각하면 분산이 작은 feature는 충분한 정보량이 없다고 판단할 수 있습니다.
저자들은 각 feature별로 unique value가 10%이하이며 frequency ratio가 19 이상인 데이터를 제거하는 방법으로 분산이 적은 feature를 제거하였습니다. 제거 결과 총 31개의 feature가 남았으며, syntactic 12개 semantic 19개가 남았습니다.
두 번째 단계는 feature normalization입니다.
각 feature마다 서로 다른 scale로 구성되어 있기 때문에 똑같은 scale로 맞춰 주어야 합니다.
저자들은 Min-Max normalization을 이용하여 각 feature를 정규화 하였습니다.
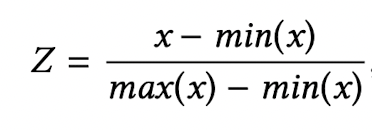
2. Experiment
저자들은 3가지 그룹으로 나눈 데이터셋에 PARAFAC2 Decomposition을 활용하여 분석하였습니다.
PARAFAC2 decomposition을 수행하기 위해 저자들은 데이터를 3D tensor로 구성하였습니다.
weak 그룹은 109개, medium 그룹은 2276개, strong 그룹은 875개의 데이터로 구성되어 있고, 각 그룹은 31개의 feature가 있으므로 저자들은 (I[3] X J X K) = ((109,2276,875) X 31 X 3)형태의 텐서로 입력 텐서를 만들었습니다. 여기서 I[3]는 각 차원의 password를 의미하며, J는 syntactic, semantic feature를 의미하여, K는 password의 level(weak, medium, strong)을 의미합니다.
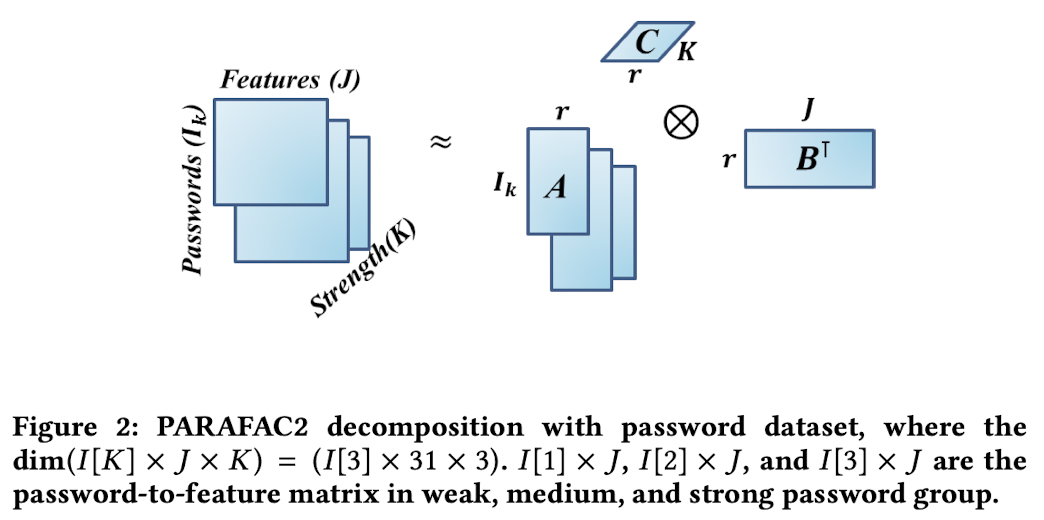
다음으로 PARAFAC2 decomposition을 수행한 결과로 앞서 구성한 3차원 텐서를 component matrix A, B, C로 분해하게 됩니다. 분해 결과로 component matrix A는 ((109,2276,875) X r) 형태의 group to factor matrix로 분해되며, 해당 matrix의 의미는 전체 strenth matrix의 각 패스워드의 factor dependancy를 의미합니다. matrix B는 (31 X r) 형태의 feature to factor matrix로 분해가 되며, 각 feature가 얼마나 factor에 영향을 받는지 나타냅니다. 마지막으로 matrix C는 (3 X r) 형태의 strength to factor matrix로 분해가 되며 factor가 얼마나 각 group에 영향을 미치는지 나타냅니다.
(여기서 r은 Rank(Factor)를 의미합니다)
다음으로 최적의 PARAFAC2 decomposition을 수행하기 위해 optimal rank r을 결정해 주어야 합니다. 저자들은 optimal rank를 결정하기 위해 R_error과 R^2_error를 이용하였습니다.
간단하게 각 지표에 대해 이야기하면, 입력 matrix X와 decomposition의 결과인 A, B, C를 이용하여 reconstruction 한 행렬 X^ 와의 차이가 어떤지 살펴보는 지표가 R_error이며 수식은 다음과 같습니다.
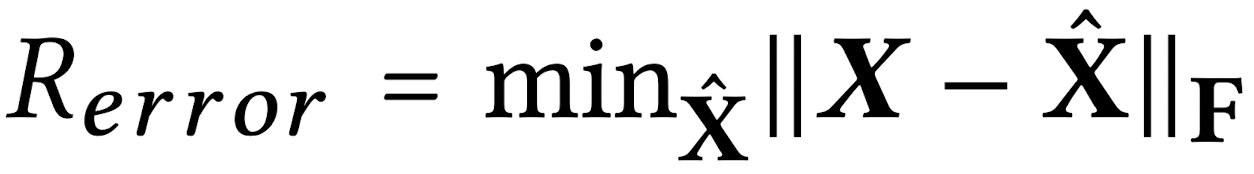
다음으로 R^2_error는 reconstruction ratio로써, 얼마나 비슷하게 복원이 되었는지 보는 지표로써 수식은 다음과 같습니다.
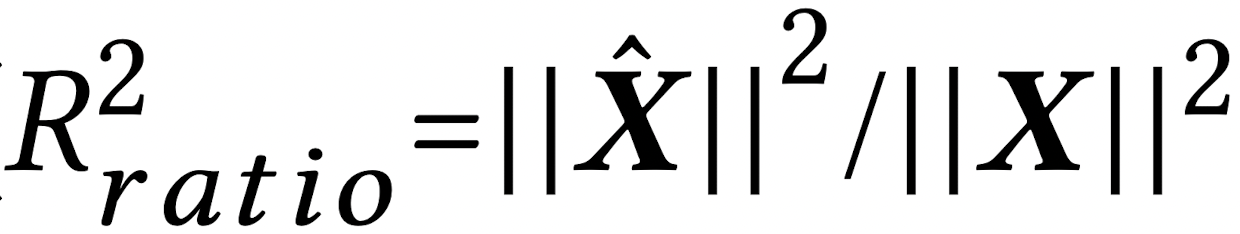
3. Result and Limitation
저자들은 이전 두 개의 지표를 이용하여 각 rank별로 10회씩 반복하여 값을 측정한 뒤 평균을 구하는 방식으로 값을 구하였습니다.
각 rank별 R_error과 R^2_ratio는 다음과 같습니다.
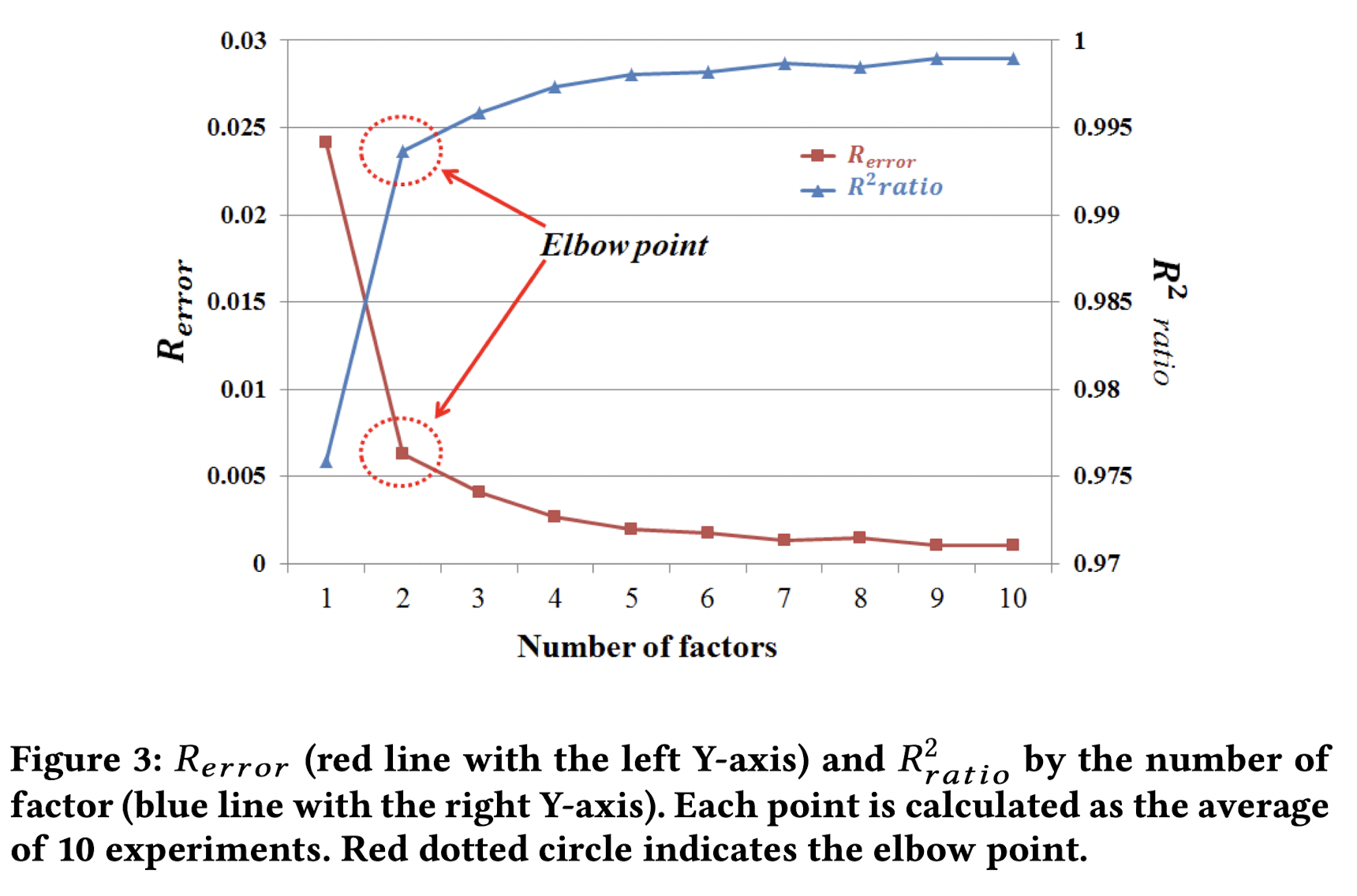
저자들은 Optimal rank 값을 설정하기 위해 rank값이 작은 r로 결정해야 합니다. 왜냐하면 r이 너무 크면 ALS(Alternative Least Square) algorithm의 성능이 나쁘기 때문입니다. 따라서 저자들은 reconstruction ratio 가 높으면서, reconstruction error가 낮을 때의 rank값들 중 rank가 가장 작은 경우의 r 값을 선택하였으며, 그래프에선 r = 2인 경우가 이에 해당합니다.
저자들은 rank 값이 2가 최적의 rank라고 설정한 다음 다시 PARAFAC2 decomposition을 수행하여 component matrix A, B, C를 구하였습니다. component matrix B가 feature to factor 관계를 나타내고 component matrix C가 group to factor 관계를 나타내므로 저자들은 두 matrix를 이용하여 strength distance를 구하였습니다.

각 feature별 factor값을 이용하여 각 group별 factor값의 거리를 측정하는 방식으로 strength distance를 구하였습니다.
거리는 Euclidean distance를 이용하였으며 수식은 다음과 같이 나타낼 수 있습니다.
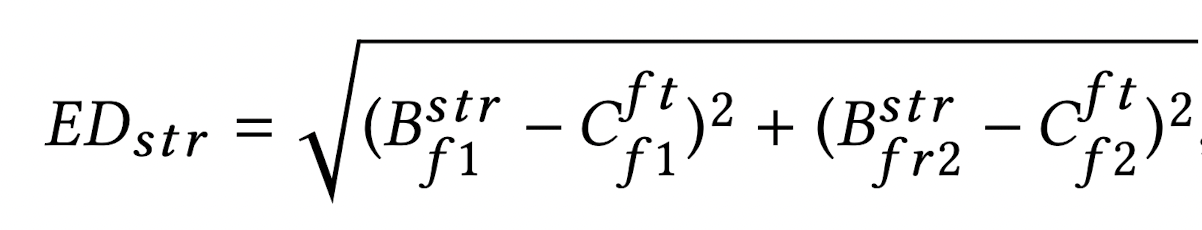
최종적으로 feature과 group 간의 strength distance값이 나오게 되며, 길이가 짧으면 짧을수록 해당 관계가 강한 관계라고 해석합니다.
실험은 총 2가지로 진행되었습니다.
첫 번째 실험은 syntactic + semantic feature (총 31개의 feature)를 사용한 경우이며, 결과는 아래 표와 같습니다.

대체적으로 많은 feature들이 weak와의 관계가 강하다고 분석할 수 있으며, 패스워드의 길이와 Strong한 패스워드의 사이의 관계가 깊은걸로 나타납니다.
다음 실험은 Semantic feature만 사용한 경우입니다.
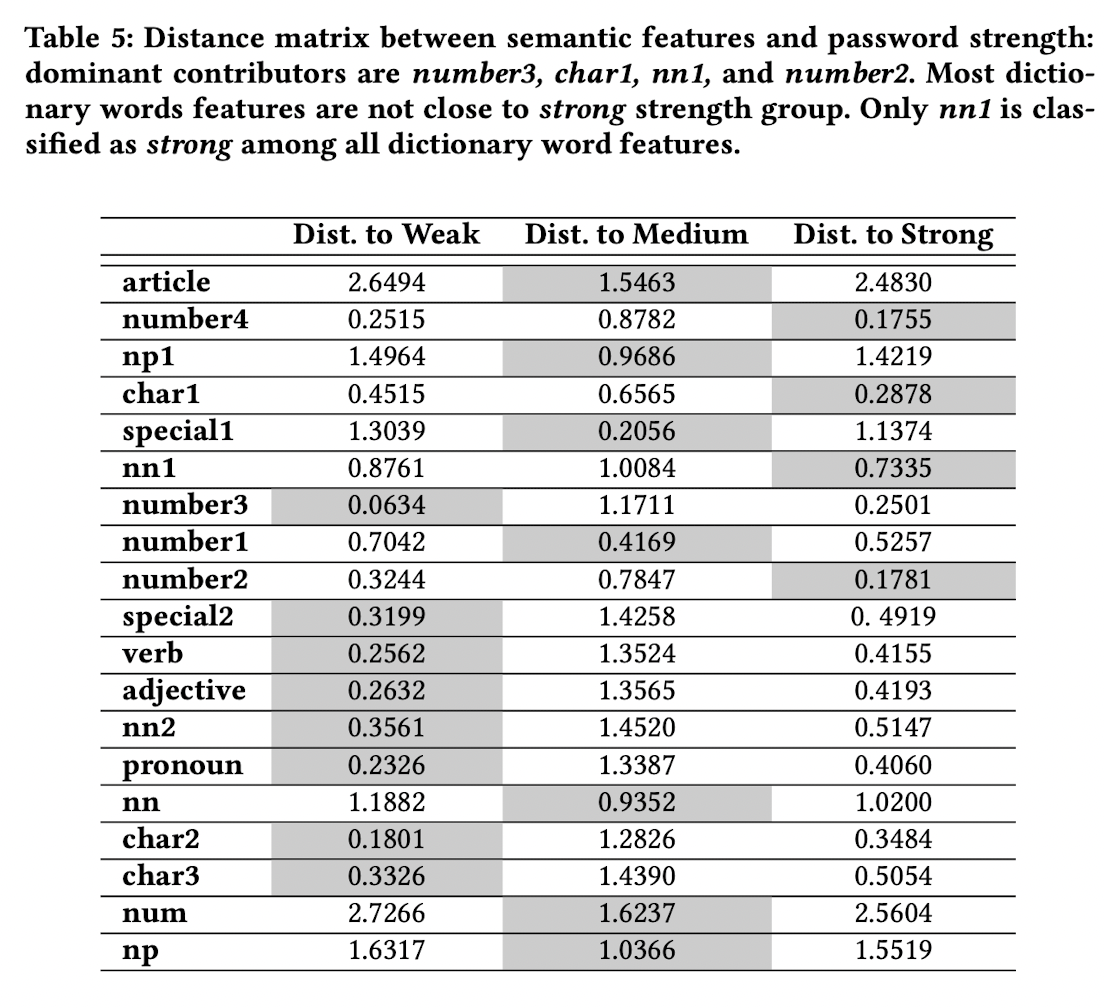
semantic feature만을 사용하였을 때는 이전 모든 feature만 사용하였을 때와 다르게 각 gruop별 특징이 나타나는 것을 볼 수 있습니다.
자세한 분석결과 해석은 논문을 참고해 주시기 바랍니다.
마지막으로, 본 논문에서 밝힌 한계는 다음과 같습니다.
한계 1. 비록 PARAFAC2 decomposition 방법이 높은 차원에서 유동성(크키가 다른 matrix 분해)을 제공해 주지만, uniqueess issue로 인해 decompostion 결괏값이 매 실험마다 다르게 나타난다는 점.
한계 2. 본 논문에서는 3200개 정도 되는 데이터로 분석하였지만, 더 많은 데이터를 이용한다면 더욱 정확하게 각 그룹별 특징을 포착할 수 있다는 점.
이상으로 What is in Your Password? Analyzing Memorable and Secure Passwords using a Tensor Decomposition 을 읽어보고 전체적인 내용들을 대해 간단히 정리해보았습니다. 개인적으로는 PARAFAC2 decomposition을 이용한 분석 방법을 처음 봐서 상당히 흥미롭게 읽었습니다. 읽고나서 진행중인 프로젝트에 실험으로 사용하기 위해 구현도 해보았는데 구현도 비교적 간단했습니다. 구현은 Tensorly를 이용하였으며 읽으시는 여러분들도 관심이 있으시다면 직접 해보는것도 추천합니다.
혹시 내용이 좀 잘못되었거나 수정이 필요한 부분을 발견하시면 언제든 댓글로 알려주시면 검토 후에 반영하도록 하겠습니다.
읽어주셔서 감사합니다.
'머신러닝(Machine Learning)' 카테고리의 다른 글
| K-means Clustering Algorithm 이해 및 구현 (0) | 2022.10.26 |
|---|
