1. 형태소 분석기의 필요성
한국어는 영어와는 다르게 토큰화(Tokenization)가 어렵습니다. 그 이유는 한국어에는 '조사', '어미' 등이 있기 때문입니다.
예를 들어, '사과' 라는 단어에 대해 조사가 붙는다고 하면 '사과가', '사과는', '사과를', '사과와' 등처럼 붙게 됩니다. 모두 '사과'를 지칭하는 말이지만, 단순히 띄어쓰기 기준(어절)으로 모두 다른 단어로 취급하게 됩니다.
또한, 띄어쓰기 기준으로 토큰화를 진행하게 된다면 띄어쓰기가 잘 되어있지 않은 문장에 대해 제대로 된 토큰화를 수행할 수 없다는 단점이 있습니다. 예를 들면, 다음과 같이 띄어쓰기 기준으로 토큰화를 한다고 하였을 때, 띄어쓰기가 제대로 되어있지 않은 문장에 대해서는 토큰화가 이루어지지 않습니다.
'나는 사과를 좋아한다' 는 ['나는', 사과를', '좋아한다']
'나는사과를좋아한다' 는 ['나는사과를좋아한다']
따라서 위와 같은 이유들로 인해, 한국어의 경우에는 형태소 분석을 진행하는 게 일반적입니다.
현재 사용할 수 있는 형태소 분석기들 중 대표적으로 사용하는 Python 라이브러리는 KoNLPy입니다.
또한 비교적 최근에 카카오가 공개한 형태소 분석기인 Khaiii 도 많이 사용하지만, 우선은 KoNLPy에 대해 정리하고자 합니다.
Khaiii 형태소 분석기의 설치와 사용방법이 궁금하신분은 이 글을 참고해주세요.
KoNLPy가 아닌 SentencePiece Tokenizer 나 WordPiece Tokenizer등 다른 토크나이저에 대해서는 추후에 글을 작성하고자 합니다!
2. KoNLPy에서 제공하는 메서드 5가지
KoNLPy는 다음과 같은 형태소 분석기를 제공합니다.
1. Hannanum : KAIST에서 개발한 형태소 분석기(1999)
2. Kkma : SNU에서 개발한 형태소 분석기
3. Komoran : Shineware에서 개발한 형태소 분석기(2013)
4. Mecab : Kyoto Univ에서 개발한 일본어용 형태소 분석기를 한국어에 적용함
5. Okt (구 Twitter) : 오픈소스 형태소 분석기
3. 공통적으로 제공하는 메서드 3가지
위 형태소 분석기들이 공통적으로 제공하는 메서드는 3가지(nouns/morphs/pos)입니다.
1. nouns : 주어진 텍스트에서 명사를 추출합니다.
2. morphs : 주어진 텍스트에서 형태소를 추출합니다.
3. pos : 주어진 텍스트에 POS tagging(문장 내에서 단어의 품사를 식별하여 태그를 추가)을 수행합니다.
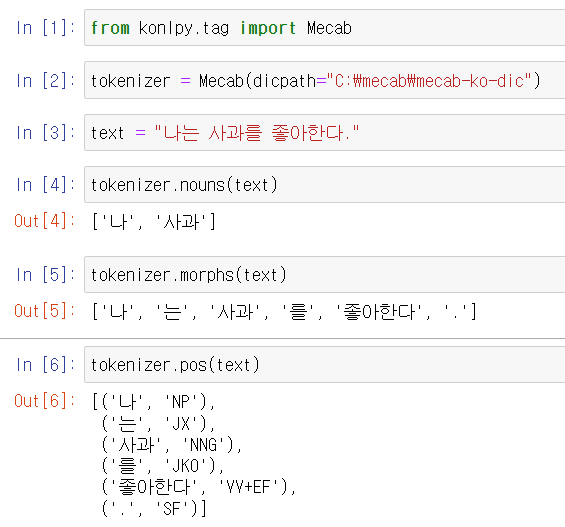
위 그림은 예시로 Mecab을 사용한 경우의 결과를 보여줍니다. nouns 함수는 문장 내의 명사인 '나'와 '사과'를 반환하는 모습을 볼 수 있으며, 입력한 문장을 형태소 별로 반환하는 morphs 함수도 볼 수 있습니다. morphs 함수는 각 토큰들이 어떤 형태소인지 알 수는 없습니다. 따라서, 각 토큰이 어떤 형태소로 구분되었는지 확인을 하려면 pos함수를 이용해야 합니다.
pos 함수는 위에서 보이는 대로 각 토큰과 형태소를 같이 보여줍니다.
3.1 pos 메서드의 입력 인자 차이점
조금 더 구체적으로 들어가면, 공통적으로 제공하는 메서드에서 nouns와 morphs가 받는 인자는 동일하지만 pos 메서드의 인자는 형태소 분석기마다 조금씩 다릅니다.
1. Hannanum.pos(phrase,ntags = 9,flatten = True)
2. Kkma.pos(phrase, flatten = True)
3. Komoran.pos(phrase,flatten = True)
4. Mecab.pos(phrase,flatten = True)
5. Okt.pos(phrase, norm = False, stem = False)
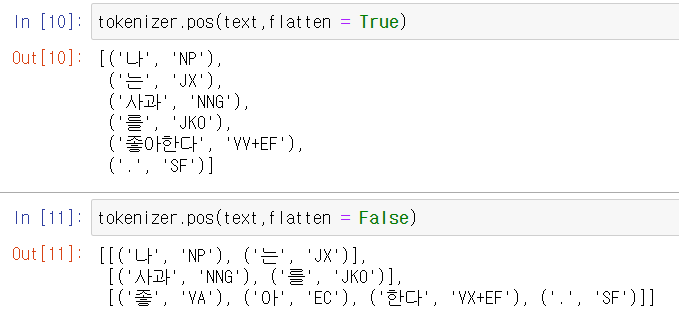
우선 Kkma,Komoran,Mecab은 모두 동일한 인자를 받는 모습을 볼 수 있습니다. 세 형태소 분석기 모두 추가 인자로 flatten을 받으며 default 값은 True입니다. flatten의 의미는 입력하는 텍스트의 어간(띄어쓰기)을 구분할지 말지 결정하는 옵션입니다.
실제로 살펴보면 다음과 같이 flatten이 True인 경우는 위에서 본 것과 같이 어간이 구분되지 않고 모두 평평하게(?) 출력됩니다. 하지만, flatten값을 False로 주게 된다면 어간을 구분해서 출력하는 모습을 볼 수 있습니다.
Hannanum에서 제공하는 인자는 flatten 이외에 ntags라는 인자가 추가로 붙어 있습니다. ntags의 의미는 태그의 수를 의미하며 9 또는 22의 값 중 선택해서 사용할 수 있습니다. 여기서 9와 22의 차이는 얼마나 자세하게 형태소를 표시하는지를 의미합니다. 실제로 아래를 보면 기본값인 9를 입력하는 경우 간단히 N, J, P, E 등과 같이 나타나지만, 22를 입력하는 경우 같은 N이라도 NP가 있고 NC가 있는 모습을 확인할 수 있습니다.

마지막으로 Okt(구 Twitter)는 다른 형태소 분석기와는 다르게 norm과 stem 인자를 받습니다. norm은 정규화를 할지 의미하며, stem은 stemming을 할지 말지에 관한 인자입니다. 실제로 '그 사과는 정말 맛이 없낰ㅋㅋ?'라는 문장을 이용하여 각 인자를 따로 추가하면 다음과 같습니다.
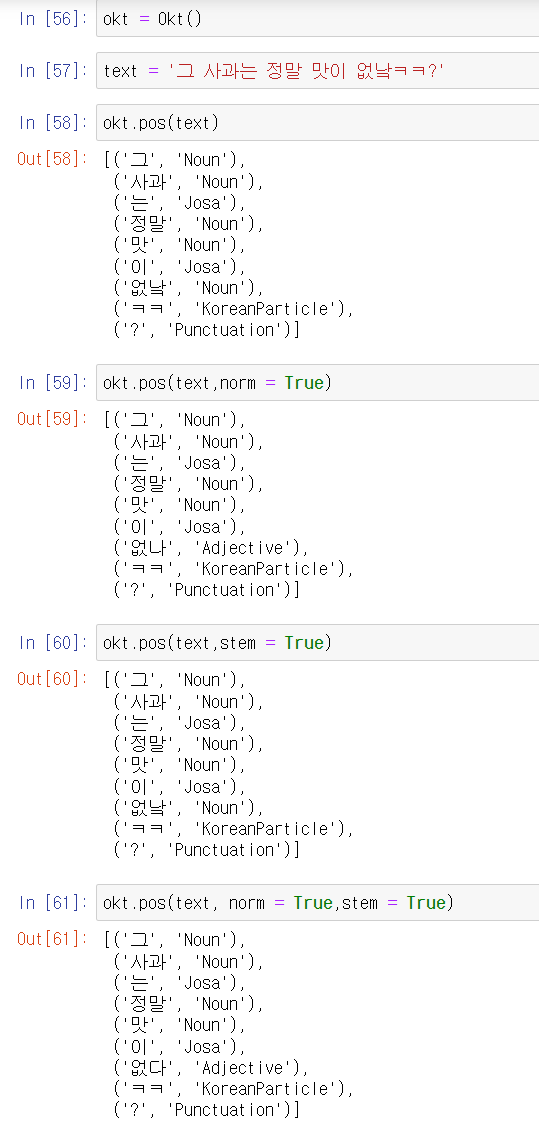
norm을 True로 설정한 경우, 원래 문장에서 '없낰' 이 '없나' 로 바뀌는 모습을 볼 수 있습니다'. 또한 norm을 True로 준 상태에서 stem을 True로 설정한 경우, 원래 문장에서 '없나'가 기본형인 '없다'로 바뀌는 모습을 볼 수 있습니다. 여기서 norm을 False로 주고 stem을 True로 준 경우에 '없낰' 이 '없낰'으로 변화가 없는 이유는 '없낰'의 기본형이 없다고 판단하기 때문입니다. 실제로 okt에서는 '없낰'을 명사로 판단하고 있습니다.
4. 독자적으로 제공하는 메서드
다음으로 공통적으로 제공하는 메서드가 아닌 독자적으로 제공하는 메서드를 살펴보면 다음과 같습니다.( - 는 없음을 의미합니다)
1. Hannanum : analyze
2. Kkma : sentences
3. Komoran : -
4. Mecab : -
5. Okt : phrase
4.1 Hannanum : analyze 메서드
Hannanum의 analyze함수는 분석 후보를 반환하는 메서드입니다. 실제로 실행을 해 보면 형태학적으로 가능한 후보를 리턴하는 모습을 볼 수 있습니다.

4.2 Kkma : sentence 메서드
Kkma의 sentences 메서드는 주어진 텍스트에서 문장을 탐지하는 메서드입니다. 만약 입력으로 주어진 텍스트가 N개의 문장으로 구성되어 있다면, N개의 문장으로 구성된 리스트를 반환합니다. 다음은 2개의 문장으로 구성된 텍스트를 입력으로 넣었을 때의 결과입니다.

4.3 Okt : phrases 메서드
마지막으로 Okt의 phrases 메서드는 입력한 텍스트의 구(phrase)를 추출합니다.

5. 여담
추가로 KoNLPy에서 제공하는 각 형태소 분석기 별 처리 속도를 보면 다음과 같다고 합니다.
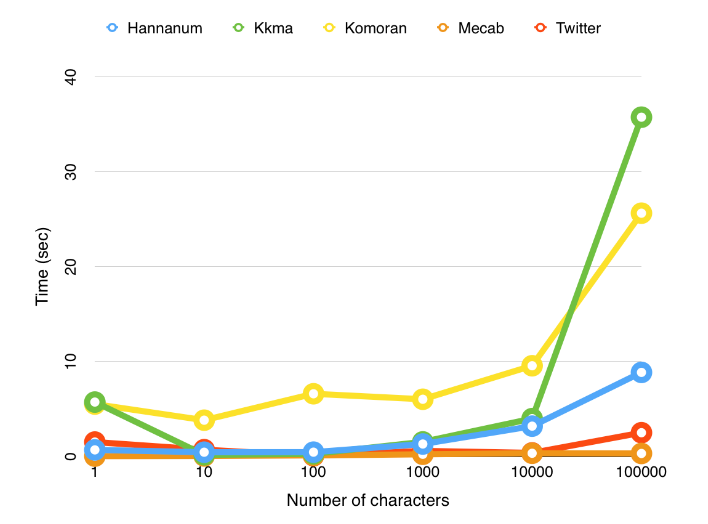
그래프만 놓고 보면 Mecab이 가장 빠르다고 나옵니다. 하지만 형태소 분석기의 성능은 처리속도와 비례하지 않습니다.
KoNLPy에서 제공하는 성능 분석표를 참고해서 본인 상황에 맞는 형태소 분석기를 사용하는 것이 바람직합니다.
앞서 초반에 언급한 형태소 분석기인 Khaiii는 아래 포스트에서 정리하였습니다.(참고로 Window 환경은 설치가 안됩니다..ㅜㅜ)
마찬가지로 Mecab도 공식적으로는 Window 지원을 하지는 않지만 설치할 수 있는 방법이 있습니다.
관련글 : https://kaya-dev.tistory.com/44
Khaiii 형태소 분석기 설치 및 사용방법
1. 개요 Khaiii 형태소 분석기는 카카오에서 공개한 오픈소스 형태소 분석기 입니다. 기존 Konlpy에서 제공하는 형태소 분석기의 공통적인 특징은 사전과 규칙기반(명사/형용사 등등)으로 형태소를
kaya-dev.tistory.com
6. 다양한 토크나이저(추가 예정)
[1] BPE(Byte Pair Encoding) Tokenizer
[2] WordPiece Tokenizer
[3] SentencePiece Tokenizer
'딥러닝(Deep Learning) > 전처리(Pre-processing)' 카테고리의 다른 글
| WordPiece Tokenizer 이해 및 정리 (1) | 2023.12.18 |
|---|---|
| Byte Pair Encoding(BPE) tokenizer 정리 (1) | 2023.12.11 |
| Khaiii 형태소 분석기 설치 및 사용방법 (0) | 2023.11.15 |


