1. 워드피스(WordPiece) Tokenizer란?
워드피스(WordPiece) Tokenizer는 Subword Tokenization의 일종으로써 주어진 텍스트를 하위단어(subword)로 쪼개는 방식입니다. 하나의 단어는 접두사 혹은 접미사가 붙어서 여러 형태로 변화할 수 있기 때문에 기존에 단어를 그대로 토큰화하는 방법보다는 유연하게 Out of Vocabulary(모델이 처음 보는 단어를 마주한 경우)에 대처할 수 있습니다. Subword tokenizer에는 여러 종류가 있지만, 이번 포스트에서는 BERT에서 사전학습에 사용한 것으로 유명한 WordPiece tokenizer에 대해 정리해보고자 합니다.
2. BPE Tokenizer와의 차이점?
Wordpiece tokenizer의 토크화 과정은 BPE와 유사한 형태이지만 차이점이 존재합니다. 첫 번째로 BPE의 경우에는 병합 순서를 저장해놓고 이후 토큰화 과정에서 활용하는 반면에 WordPiece는 병합 순서를 따로 저장해놓지 않습니다. 두 번째로 BPE는 병합할 문자를 선택할 때 가장 빈번하게 출현하는 문자 쌍을 우선적으로 병합하지만, WordPiece의 경우에는 결합확률(Joint probablity(혹은 likelihood라고도 부릅니다))를 계산하여서 확률이 높은 문자 쌍을 우선적으로 결합합니다. BPE tokenizer에 대해서는 'BPE Tokenizer 이해 및 정리' 글을 참고해 주시기 바랍니다!
3. WordPiece Tokenizer 작동방식
WordPiece는 BPE와 동일하게 하나의 텍스트를 분할하는 것 부터 시작합니다. 텍스트를 문자 단위로 분할할 때 BERT의 경우에는 접미사 '##'를 추가하여 subword를 식별합니다. 예를 들어 'token'이라는 단어에 대해서는 다음과 같이 분할됩니다.
(t, '##o', '##k', '##e', '##n')
좀 더 많은 텍스트를 예를 들어 한번 살펴봅시다. Pre-tokenize를 실행한 이후 코퍼스에 포함된 단어들이 다음과 같다고 가정해 봅시다.각 괄호의 왼쪽은 단어, 오른쪽은 빈도수를 의미합니다.
Corpus(word, frequency) : ("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
위 단어들을 분할하면 다음과 같이 분할이 될 것입니다.
Corpus : ("h" "##u" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("h" "##u" "##g" "##s", 5)
이제 코퍼스에 포함된 고유한 문자를 모아서 vocabulary를 구성하면 다음과 같습니다.
["b", "h", "p", "##g", "##n", "##s", "##u"]
다음으로 할 작업은 병합입니다. BPE는 가장 연속되는 문자 쌍 중 가장 많이 출현하는 문자 쌍을 우선적으로 병합하지만, WordPiece는 아래 식을 이용하여 병합 순서를 결정합니다.
$$ Score(a,b) = \frac{freq(a,b)}{ freq(a) freq(b)}$$
즉, 두 문자 쌍이 동시에 출현한 횟수를 각 문자의 출현 횟수의 곱으로 나눠주는 방식으로 계산합니다. 예를 들어 'h'와 '##u'의 score를 계산하면 다음과 같습니다.
$$ Score(h,\#\#u) = \frac{freq(h, \#\#u)}{freq(h)freq(\#\#u)} = \frac{15}{15\times 36} = \frac{1}{36}$$
'##u'가 모든 단어에 포함되어 있으므로 score를 구할 때 '##u'는 모두 같은 값으로 계산이 됩니다. 다른 쌍에 대해서도 계산을 해보면 ("##g", "##s")이 \( \frac{1}{20} \) 로 가장 점수가 높음을 알 수 있습니다. 따라서 첫 번째 병합은 ("##g", "##s") -> ("##gs")입니다.
병합할 대상이 정해졌으니 코퍼스에 포함된 모든 단어에 대해 적용해 주고, vocabulary에도 추가해주어야 합니다. 정리하면 다음과 같습니다.
Vocabulary: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs"]
Corpus: ("h" "##u" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("h" "##u" "##gs", 5)
다음 병합도 살펴보겠습니다. 코퍼스를 살펴보면 '##u'가 모든 분할된 문자들의 가운데에 위치하므로 어떤 문자 쌍의 점수를 계산하든 '##u'가 반드시 포함됩니다. 따라서 계산에 의해 모두 점수가 똑같을 수밖에 없습니다. 이러한 경우에는 가장 첫 번째에 위치한 쌍을 병합합니다. 따라서 두 번째 병합은 ("h", "##u") -> "hu"입니다.
이전과 마찬가지로 모든 코퍼스에 적용하고 vocabulary에 추가하면 다음과 같습니다.
Vocabulary: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs", "hu"]
Corpus: ("hu" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("hu" "##gs", 5)
마지막으로 한번 더 해보겠습니다. 마찬가지로 모든 병합 쌍에 대해 계산을 하게 되면 'hu'와 '##gs'가 \( \frac{1}{15} \)로 가장 높은 값을 가지게 되므로 세 번째 병합은 ('hu', '##gs') -> 'hugs'입니다.
이전과 마찬가지로 모든 코퍼스에 적용하고 vocabulary에 추가하면 다음과 같습니다.
Vocabulary: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs", "hu", "hug"]
Corpus: ("hu" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("hugs", 5)
BPE에서 수행한 것과 마찬가지로 원하는 Vocabulary의 크기에 도달할 때까지 위 작업을 반복하면 WordPiece Tokenizer는 완성됩니다.
이렇게 학습 결과로 얻은 Vocabulary를 이용하여 새로운 텍스트를 어떻게 토큰화하는지 살펴보겠습니다.
예를 들어 기존 코퍼스에는 존재하지 않았던 'bugs'를 예로 들어보겠습니다.
new corpus : 'bugs'
우선 시작 부분인 'b'를 기준으로 가장 긴 subword가 vocabulary에 있는지 체크합니다. vocabulary에서 확인을 해 보니 'b'가 가장 긴 하위단어로 있으므로, 중간 결과는 다음과 같습니다.
'bug' -> ('b', '##ugs')
다음으로 살펴볼 하위 단어는 '##ugs' 입니다. 마찬가지로 '##ugs'의 '##u'를 기준으로 살펴보면 '##u'가 가장 긴 하위단어 입니다. 따라서 다음 중간 결과는 다음과 같습니다.
'bug' -> ('b', '##ugs') -> ('b', '##u', '##gs')
다음으로 살펴 볼 subword는 '##gs'입니다. 똑같이 '##g'로 시작하는 subword 중 가장 긴 subword를 찾아보면 '##gs'가 vocabulary에 있으므로 '##gs'는 '##gs'로 나눠지게 되므로 최종 결과는 다음과 같습니다.
'bug' -> ('b', '##ugs') -> ('b', '##u', '##gs')
Question!!
토큰화 학습 이후, Vocabulary에는 없는 새로운 문자가 포함된 단어를 토큰화하면 어떻게 될까?
1) 'mugs'를 토큰화하는 경우에는 어떻게 될까?
BPE tokenizer의 경우에는 모든 토큰을 나누어서 병합 규칙에 따라 병합을 진행하지만, WordPiece의 경우에는 나누는 과정에서 vocabulary에 존재하지 않는 하위 단어가 발생하면 'Unknown'으로 처리합니다. 특수 토큰 중 ['UNK']가 이에 해당합니다.
즉, 'mug'도 마찬가지로 토큰화를 진행하게 되면, 시작 지점으로 가장 긴 subword를 vocabulary에서 찾게 되므로 'm'으로 시작하는 subword를 찾게 됩니다. 하지만 'm'은 vocabulary에 존재하지 않으므로, 'mugs'는 ['UNK']로 토큰화됩니다.
Tokenization) 'mugs' -> ('UNK')
2) 'bum'을 토큰화하는 경우에는 어떻게 될까?
'bum'을 토큰화하게 되면, 시작 지점에 있는 'b'로 시작하는 가장 긴 subword를 vocabulary에서 찾게 되므로 다음과 같이 됩니다.
'bum' -> ('b', '##um')
다음으로 '##u'로 시작하는 subword를 찾은 후에 토큰화를 해주면, 다음과 같이 토큰화할 수 있을 것 같습니다.
'bum' -> ('b', '##u', '##m')
마지막으로 '##m'로 시작하는 subword를 vocabulary에서 찾아보면 존재하지 않으므로 다음과 같이 진행될 것 같습니다.
'bum' -> ('b', '##u', '##m') -> ('b', '##u', 'UNK')
하지만, WordPiece에서는 모르는 subword가 발생하면 전체 토큰을 'UNK'로 처리하므로 다음과 같이 토큰화하는 것이 올바릅니다. 이 부분은 처음 보는 subword만 'UNK' 처리하는 BPE와는 차이가 있습니다.
Wrong(X) : 'bum' -> ('b', '##u', '##m') -> ('b', '##u', 'UNK')
Correct(O) : 'bum' -> ('UNK')
3. WordPiece 구현하기
이전 BPE Tokenizer 구현하기에서 사용했던 예제 코퍼스를 활용하겠습니다.
"This is the Hugging Face course."
"This chapter is about tokenization."
"This section shows several tokenizer algorithms."
"Hopefully, you will be able to understand how they are trained and generate tokens."
우선, WordPiece를 구현하기 전, 예제로 사용하는 코퍼스를 pre-tokenize 하기 위해 BERT Tokenizer를 불러와줍니다. BERT에서 사용하는 tokenizer는 wordpiece이고, pre-tokenize를 지원해 줍니다.
#BERT 모델은 WordPiece tokenizer를 사용하므로 사전학습된 BERT Tokenizer를 불러와서 pre-tokenizer로 사용한다.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
다음으로는 코퍼스를 다음과 같이 저장해 줍니다. 이전 설명에서 사용한 예제도 직접 해보기 위해 'test'라는 변수에 저장하였습니다. 단, 이후 진행되는 구현에서는 corpus 변수에 저장된 텍스트를 가지고 구현합니다. 아래 test변수를 사용하기 위해서는 간단한 수정이 필요하므로 참고해 주시면 됩니다.
#BPE Tokenizer에서 사용한 예제 코퍼스를 여기서도 그대로 사용한다.
corpus = [
"This is the Hugging Face course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
#설명예제
#("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
test = [
"hug hug hug hug hug hug hug hug hug hug",
"pug pug pug pug pug bun bun bun bun",
"hugs hugs hugs hugs hugs",
"pun pun pun pun pun pun pun pun pun pun pun pun"
]
다음으로는 defaultdict를 이용하여 pre-tokenize 된 토큰들의 고유 개수를 세어줍니다. word_freqs 변수에는 key로 토큰이, value값으로는 해당 토큰의 출현 횟수가 담겨 있습니다.
from collections import defaultdict
word_freqs = defaultdict(int)
for text in corpus:
#pretokenize 시행하기
#BPE와 마찬가지로 단어,시작범위,끝범위로 알려준다.
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text.lower())
#print(words_with_offsets)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
word_freqs
다음으로는 각 토큰을 살펴가면서 초기 vocabulary를 만들어줍니다.
alphabet = []
for word in word_freqs.keys():
if word[0] not in alphabet:
alphabet.append(word[0])
for letter in word[1:]:
if f"##{letter}" not in alphabet:
alphabet.append(f"##{letter}")
alphabet.sort()
print(alphabet)
또한 초기 vocabulary에 특수 토큰을 추가해 줍니다. BERT에서 사용하는 특수 토큰은 ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"]가 있습니다. "[PAD]"는 입력 최대길이인 max_length보다 작은 코퍼스에 추가를 해 줘서 길이를 맞춰주는 토큰이며(padding), "[UNK]"는 vocabulary에 없는 토큰을 의미하며, "[CLS]"는 입력 문장의 시작 부분을 알려주는 토큰이며, "[SEP]"은 사전학습 시 BERT의 입력 문장은 2개인데, 이 두 문장의 사이에 집어넣어서 구분하는 토큰이며, "[MASK]"는 사전학습 시 임의의 토큰을 마스킹하게 되는데, 이때 사용하는 토큰으로써 모델은 "[MASK]"가 된 토큰이 무엇인지 맞추게 됩니다.
vocab = ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"] + alphabet.copy()
다음으로는 word_freqs에 있는 토큰을 하나의 문자로 나누는 작업을 진행합니다. 예를 들어 "word"의 경우에는 ["w", "##o", "##r", "##d"]로 나뉘게 됩니다.
splits = {
word: [c if i == 0 else f"##{c}" for i, c in enumerate(word)]
for word in word_freqs.keys()
}
이제 위의 작업으로 우리는 토큰과 그 빈도수를 저장해 놓은 'word_freqs' 변수와 토큰과 해당 토큰을 문자로 쪼개놓은 'splits' 변수와 각 고유 문자가 저장되어 있는 'vocab'변수가 있습니다. 이제 이 변수들을 이용하여 다시 병합하는 과정을 진행합니다. 앞서 설명에서 말했다시피 연속되는 각 문자의 쌍의 출현 빈도를 이용하여 점수를 구한 뒤, 해당 점수가 가장 높은 문자 쌍을 우선적으로 병합합니다. 따라서 문자 쌍의 점수를 구하는 함수를 하나 정의 합니다.
def compute_pair_scores(splits):
letter_freqs = defaultdict(int)
pair_freqs = defaultdict(int)
for word, freq in word_freqs.items():
split = splits[word]
if len(split) == 1:
letter_freqs[split[0]] += freq
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
letter_freqs[split[i]] += freq
pair_freqs[pair] += freq
letter_freqs[split[-1]] += freq
scores = {
pair: freq / (letter_freqs[pair[0]] * letter_freqs[pair[1]])
for pair, freq in pair_freqs.items()
}
return scores
위 함수를 이용해서 각 단어 쌍의 점수를 구합니다. 실제로 어떻게 출력되는지도 살펴봅니다.
pair_scores = compute_pair_scores(splits)
for i, key in enumerate(pair_scores.keys()):
print(f"{key}: {pair_scores[key]}")
if i >= 4:
break
이제 점수가 가장 높은 쌍을 구할 차례입니다.
best_pair = ""
max_score = None
for pair, score in pair_scores.items():
if max_score is None or max_score < score:
best_pair = pair
max_score = score
print(best_pair, max_score)
실제로 실행해 보면 ('a', '##b') 쌍이 점수가 0.2로 가장 높음을 알 수 있습니다.
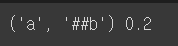
따라서 ('a', '##b') -> 'ab'의 병합이 가장 첫 번째 병합이 됩니다. 병합 후의 결과를 vocab에 추가해 줍니다.
vocab.append("ab")
다음으로는 병합 규칙에 따라 기존 문자들을 병합해주어야 합니다. merge_pair 함수는 두 문자 a, b와 splits 변수를 입력으로 받게 되면 a와 b의 병합을 splits에 적용하는 함수입니다.
def merge_pair(a, b, splits):
for word in word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
merge = a + b[2:] if b.startswith("##") else a + b
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splits
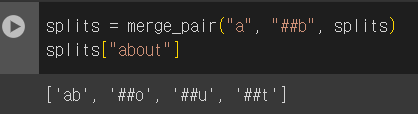
위 함수를 실행해 보고, 'a'와 '##b'가 포함된 'about'이 어떻게 바뀌었는지 살펴봅니다.
splits = merge_pair("a", "##b", splits)
splits["about"]
실행해 보면 'a'와 '##b'가 하나의 'ab'로 병합되었음을 확인할 수 있습니다.
위의 과정을 이제 우리가 원하는 vocab_size가 될 때까지 병합을 계속해줍니다. 우선 vocab_size를 100으로 설정해 놓고 실행해 보았습니다.
vocab_size = 100
while len(vocab) < vocab_size:
scores = compute_pair_scores(splits)
best_pair, max_score = "", None
for pair, score in scores.items():
if max_score is None or max_score < score:
best_pair = pair
max_score = score
#print(max_score)
splits = merge_pair(*best_pair, splits)
new_token = (
best_pair[0] + best_pair[1][2:]
if best_pair[1].startswith("##")
else best_pair[0] + best_pair[1]
)
vocab.append(new_token)
여기까지 WordPiece에 대한 학습은 끝입니다. 다음으로는 기존에 없는 새로운 문장을 입력하면, 우리가 학습시킨 WordPiece를 이용하여 토큰화하는 방법입니다. 과정은 학습과 마찬가지로 pre-tokenize를 먼저 시행하고, 단어와 문자로 분리합니다. 다음으로는 가장 첫 번째에 위치한 문자로 시작하는 가장 긴 subword를 탐색하고 나누게 됩니다. 다음에는 그다음에 위치한 문자로 시작하는 가장 긴 subword를 vocab에서 탐색하고 나누면서 계속 반복해서 작업을 이어나갑니다.
def encode_word(word):
word = word.lower()
tokens = []
while len(word) > 0:
i = len(word)
while i > 0 and word[:i] not in vocab:
i -= 1
if i == 0:
return ["[UNK]"]
tokens.append(word[:i])
word = word[i:]
if len(word) > 0:
word = f"##{word}"
return tokens
위 함수를 실행해서 'Hugging'과 'HXgging'의 실행 결과를 비교해 보겠습니다.
print(encode_word("Hugging"))
print(encode_word("HXgging"))
위 코드를 실행하면 다음과 같은 결과가 나옵니다.
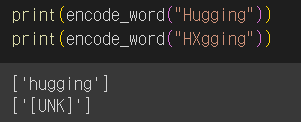
'x'는 vocab에 포함되어있지 않은 새로운 문자이므로 전체 토큰화 결과가 "[UNK]"로 출력됨을 알 수 있으며, 반대로 "Hugging"은 하나의 토큰으로 토큰화되었음을 알 수 있습니다.
이제까지의 코드를 종합하여 하나의 문장을 입력하면 토큰화된 결과를 출력하는 함수를 만들어보겠습니다.
def tokenize(text):
pre_tokenize_result = tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text.lower())
pre_tokenized_text = [word for word, offset in pre_tokenize_result]
encoded_words = [encode_word(word) for word in pre_tokenized_text]
return sum(encoded_words, [])
print(tokenize("This is the Hugging Face course!"))
토큰화 결과는 다음과 같이 출력됩니다.

'자연어 처리(NLP) > 전처리(Pre-processing)' 카테고리의 다른 글
| Tokenizer : 기본적인 토큰화(Tokenization) 방법 (0) | 2024.09.26 |
|---|---|
| Byte Pair Encoding(BPE) tokenizer 정리 (1) | 2023.12.11 |
| Khaiii 형태소 분석기 설치 및 사용방법 (0) | 2023.11.15 |
| Tokenizer : 한국어 형태소 분석기의 종류와 사용 방법 (2) | 2022.07.26 |



