0. Introduction
기본적으로 언어를 입력받는 모델은 바로 텍스트(원시 문자열)를 입력받지 못합니다. 이는 시계열 데이터와 같이 숫자로 이루어진 데이터가 아니기 때문입니다. 따라서 우리는 모델에 텍스트를 입력하기 위해 원시 문자열을 숫자의 형태로 바꿔 줄 필요가 있습니다. 이때 원시 문자열을 숫자로 바꾸는 과정을 '임베딩(Embedding) 혹은 토큰화(Tokenization)' 이라고 합니다.(가끔은 인코딩(encoding)이라고 부르는 분들도 있습니다) 이번 포스트에서는 가장 기본적인 형태의 토큰화 방법에 대해 정리하고자 합니다.
1. 문자 토큰화(Character-based tokenization)
가장 간단한 토큰화 방법은 각 문자를 1,2,3 과 같이 숫자로 바꿔서 모델에 입력하는 방법입니다. 우선 예시로 "Tokenizing text is a core task of NLP." 를 사용하겠습니다.
문장이 주어졌으면 가장 처음 해야 하는일은 각 문장에 포함 된 문자열들을 하나씩 분리해 주는 일을 해야합니다.

위와 같이 python의 list를 이용하여 각각의 문자(토큰)로 분리 하였으면, 각 문자에 고유한 정수를 부여하면 됩니다.

이제 만들어진 dictionary를 이용하여 개별 토큰을 숫자로 바꾸어 줍니다.

여기까지 하면 일단은 문자를 숫자로 바꾸어주는 작업에 성공한 것 처럼 보입니다. 하지만, 위의 방식처럼 단순히 정수로 인코딩하는 방법은 문자(token) 사이에 가상의 순서가 만들어 진다는 문제가 있습니다.(예를들어 a는 6으로 매핑되고, c는 7로 매핑되었을 때, 두 숫자를 더한 13은 ac가 아닌 n으로 매핑되어 있습니다. 반대로 두 숫자의 차를 생각해봐도 연관성이 없어보입니다.) neural network는 관계를 학습하는 능력이 뛰어난데, 실제로 토큰 사이에는 아무런 관계가 없기 때문에 잘못된 관계를 학습 할 수 있습니다. 이러한 문제를 해결하기 위해서 one-hot encoding을 활용해 볼 수 있습니다.
pytorch를 이용하면 쉽게 one-hot vector로 변환할 수 있습니다.
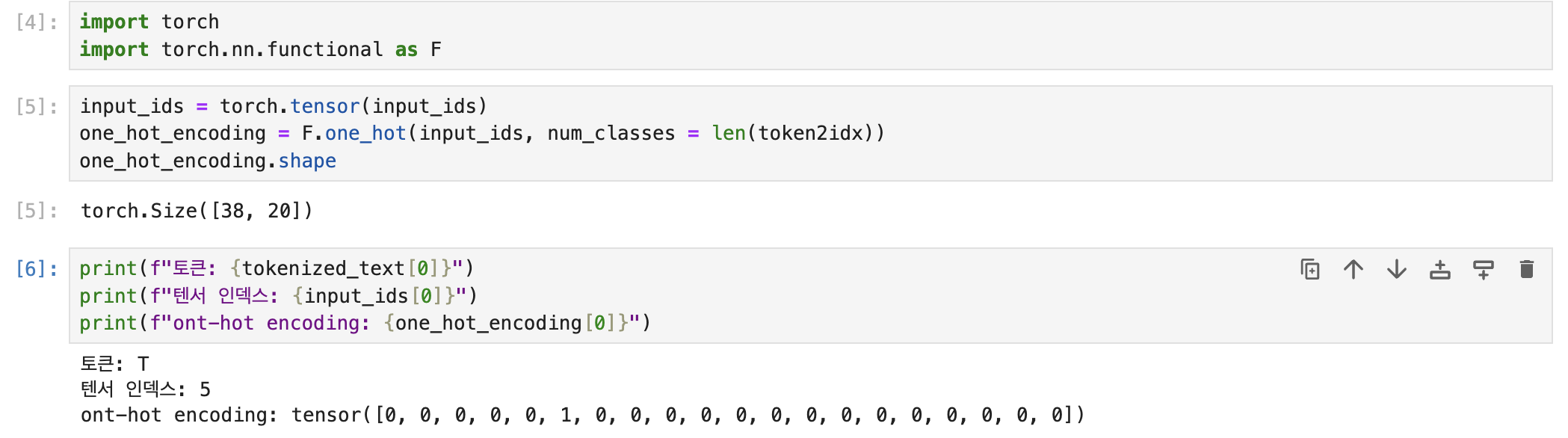
One-hot vector로 만든 결과를 보면 입력한 텍스트의 길이가 38이고 고유한 문자가 20개 였으므로 38x20 사이즈를 가지는 one-hot vector가 만들어 졌음을 알 수 있습니다. 또한 실제로 토큰에 해당하는 one-hot vector를 출력하면 인덱스가 5이고, 5번째에 해당하는 부분이 1로 표시되었음을 알 수 있습니다.
위 방식은 매우 간단히 텍스트를 토큰화 할 수 있으며, 철자가 틀렸거나 희귀한 단어도 처리하기에 유용합니다. 하지만, 단어나 문장 같은 언어 구조를 우리가 만든 one-hot vector로 학습해야 한다는 큰 단점이 있습니다. 세상에는 수 많은 단어가 존재 하므로 각각의 문자를 이용하여 단어를 학습한다는 것은 상당히 비 효율적이라고 보여집니다.
문자 토큰화의 장단점
- 장점 1. 철자 오류 및 희귀한 단어를 처리하는데 유용하다
- 장점 2. 간단히 학습에 나타난 모든 문자에 대해 처리가 가능하다.
- 단점 1.단어나 문장 같은 언어 구조를 이 데이터에서 학습해야 하기 때문에 비용이 크다
- 단점2. 모델 평가 시 새로운 문자에 대해 처리하기 어렵다.
- 단점3. 문자가 많으면 많을 수록 메모리를 많이 사용해야 한다.
2. 단어 토큰화(word Tokenization)
하나의 개별 문자로 단어를 학습해야하는 단점을 극복하기 위해 이번에는 단어 수준에서 토큰화를 진행하면 조금 더 문제가 쉬워질 것 같습니다. 단어 토큰화(word tokenization)은 문자 토큰화와는 다르게 단어를 학습하는 단계가 생략되기 때문에 훈련 과정의 복잡도가 감소 합니다. 하지만 위의 방식대로(정수 encoding 방식) 단어를 토큰화한다면 구두점이 고려되지 않는 문제가 발생합니다.
예를들면 "NLP."이 하나의 토큰으로 처리됩니다. 또한 단어에 곡용(declination), 활용형, 철자 오류가 있어도 하나의 토큰으로 처리하기 때문에 어휘 사전이 급격히 커질 수 있습니다.
위의 방식을 해결하기 위해서 어간 추출(Stemming)이나 표제어 추출(Lemmatization)을 적용해 볼 수 있습니다.
- 어간 추출: Stemming이란 어형이 변형된 단어로부터 접사 등을 제거하고 그 단어의 어간을 분리해내는 것을 의미합니다. 예를 들어, ‘automate’, ‘automatic’, ‘automation’ 이렇게 세개의 단어가 있다고 가정해봅시다. 이들은 각각 ‘e’, ‘ic’, ‘ion’이라는 접사를 가지고 있어 어형이 변형되었지만 모두 ‘automat’라는 어간을 가지고 있습니다. 이러한 단어들에 대하여 접사를 제거하고 동일한 어간인 ‘automat’으로 매핑되도록 하는 작업이 stemming입니다.
- 표제어 추출: Lemmatization은 한 단어가 여러 형식으로 표현되어 있는 것을 단일 형식으로 묶어주는 기법입니다. 예를 들어, ‘am’, ‘are’, ‘is’ 세개의 단어에 대하여 lemmatization을 실시할 경우 그 결과는 ‘be’가 됩니다.
(자세한 내용 및 출처 : https://cheris8.github.io/data%20analysis/TP-Stemming-Lemmatization/)
여기서는 Stemming이나 Lemmatization은 적용하지 않고, 간단히 단어 토큰화를 이전과 같은 방법으로 진행해보겠습니다.

결과를 보면, 위에서 언급한대로 "NLP."는 하나의 단어로 취급하는 모습을 볼 수 있습니다. 또한 문장에 core,cora,corx 등의 단어가 포함되어 있었다면 각각 하나의 단어로 취급될 것이라고 예상할 수 있습니다.
이처럼 단어 토큰화(Word Tokenization) 방법은 어휘 사전의 크기가 매우 커질 수 있다는 단점이 존재합니다. 어휘 사전이 커진다는 의미는 모델의 파라메터(Parameter)도 커진다는 의미합니다. 예를들어 100만개의 어휘 사전이 존재하며, 모델의 첫번째 layer에서 1000차원의 벡터로 압축한다고 가정해봅시다. 우리는 모델에 텍스트를 입력할때 one-hot encoding을 거치게 됩니다. encoding된 vector의 차원은 100만이 되며, 첫번째 layer의 차원은 1000 이므로 첫번째 layer의 가중치 행렬의 크기는 100만 x 1000개 = 10억개의 가중치를 갖게 됩니다. 따라서 모델 학습에 들어가는 비용도 커지게 됩니다.
이러한 문제를 해결하기 위해서 일반적으로는 어휘 사전의 크기를 제한하게 됩니다. 예를들어 100만개의 어휘 사전에서 자주 등장하는 어휘 10만개만 사용한다고 가정해봅시다. 그렇다면 나머지 90만개의 어휘는 잘 사용되지 않으므로 'Unknown' 으로 분류하여 학습할 수 있습니다. 하지만 이 방법은 토큰화 과정에서 일부 중요한 정보를 잃을 수 있다는 단점이 존해합니다.
3. 하위 단어 토큰화(Subword tokenization)
위와 같은 단점을 해결하기 위해 제안된 방법이 하위 단어 토큰화(SubWord Tokenization) 방법입니다. 하위 단어 토큰화 방법은 모든 입력 정보와 일부 입력 구조를 유지합니다. 즉, 문자 토큰화(Character-based Tokenization)의 장점과 단어 토큰화(Word Tokenization)의 장점을 결합한 방법입니다.
하위 단어 토큰화에 대해 조금 더 자세한 설명은 제 글을 참고해 주세요!
- BPE Tokenizer 정리 : https://kaya-dev.tistory.com/46
- WordPiece Tokenizer 정리 : https://kaya-dev.tistory.com/47
우선 WordPiece tokenizer를 사용하는 DistilBERT tokenizer를 사용하여 토큰화를 진행 해 보겠습니다.

- Transformers에서 제공하는 AutoTokenizer를 사용하면 쉽게 불러올 수 있습니다.
- 이제 불러온 Tokenizer를 이용하여 토큰화를 진행해 보겠습니다.

문자 기반 토큰화와 단어 토큰화 처럼 텍스트가 고유한 정수로 매핑된 모습을 확인 할 수 있으며, attention_mask도 포함된 모습을 볼 수 있습니다.
우선 input_ids에 나타난 숫자를 다시 토큰으로 변환해봅시다.

토큰으로 변환하였더니 입력에는 없었던 [CLS]와 [SEP]이 추가된 모습을 볼 수 있었으며, ##izing 이나 ##p로 토큰화가 된 모습을 볼 수 있습니다. 또한 모든 문자가 소문자로 변환된 모습도 볼 수 있습니다.
여기서 [CLS]와 [SEP]은 특수 토큰으로써, [CLS]는 문장의 시작을 의미하는 특수 토큰이고, [SEP]은 문장의 끝을 의미하는 특수 토큰입니다. 또한 #의 의미는 앞의 문자열이 공백이 아님을 의미합니다. 따라서 문자열로 다시 합칠때 공백으로 합치지 않고 앞의 문자열로 바로 합치게 됩니다.
다시 위의 토큰을 이용하여 원래 문장으로 변환하면 다음과 같습니다.

처음에 우리가 입력한 문장이 소문자로 변환되었고 특수 토큰이 자동으로 추가되었음을 확인할 수 있습니다.
우리가 불러왔던 DistillBERT Tokenizer는 사전학습된 문서에서 만든 어휘 사전입니다. 따라서 이미 학습된 어휘들이 사전에 담겨 있습니다. 어휘 사전의 크기를 살펴보면 다음과 같이 살펴볼 수 있습니다.

DistilBERT는 총 30522개의 어휘사전을 가지고 학습했음을 알 수 있습니다.
'자연어 처리(NLP) > 전처리(Pre-processing)' 카테고리의 다른 글
| WordPiece Tokenizer 이해 및 정리 (1) | 2023.12.18 |
|---|---|
| Byte Pair Encoding(BPE) tokenizer 정리 (1) | 2023.12.11 |
| Khaiii 형태소 분석기 설치 및 사용방법 (0) | 2023.11.15 |
| Tokenizer : 한국어 형태소 분석기의 종류와 사용 방법 (2) | 2022.07.26 |



