1. 개요
Khaiii 형태소 분석기는 카카오에서 공개한 형태소 분석기입니다. 기존 Konlpy에서 제공하는 형태소 분석기의 공통적인 특징은 사전과 규칙기반(명사/형용사 등등)으로 형태소를 분석해 주는 반면, khaiii는 데이터 기반 알고리즘을 이용해서 분석하였다고 합니다.
사용한 데이터의 양은 85만 문장과 천만 어절의 코퍼스를 이용하였습니다.
khaiii가 데이터를 가지고 형태소 분석기를 만들 때 사용한 기계학습 알고리즘은 CNN(Convolution Neural Network)입니다. 대규모 언어 모델을 학습하기 위해서는 엄청난 양의 문장을 전처리 해야 하기 때문에 속도가 빠른 CNN을 사용한 것으로 보입니다.

Khaiii는 어떤 단어의 주변단어의 갯수(Window size)와 임베딩 차원(Embedding Dimension)에 변화를 주면서 성능을 측정하였습니다. 성능 측정 지표로는 정밀도 점수(Precision score)와 재현율 점수(Recall score)의 조화평균인 F-score를 사용하였습니다.
표에서 볼 수 있듯이 window size가 3~4일 때 가장 성능이 좋으며, Embedding dimension이 150 이상일 때 성능이 좋음을 확인 할 수 있습니다. 그림에서 볼 수 있듯이 embedding dimension이 점점 커질수록 F-score도 좋아지지만, 임베딩 차원이 커지면 커질수록 시간이 오래 걸리는 단점이 있습니다. 따라서 embedding dimension이 작으면서 F-Score 값이 95 이상이면서 모델의 크기가 작은 모델은 win=3, emb=30이며 F-Score는 95.30입니다.
2. 설치 방법
khaiii 설치 방법은 공식 깃허브 페이지에서 소개하고 있습니다. 공식 설치 환경은 Linux와 MacOs가 필요하며, 아쉽게도 Windows에서는 설치가 불가능합니다.
우선 khaiii 깃허브를 clone해옵니다. 설치가 완료되었으면 khaiii 폴더로 이동해줍니다.
git clone https://github.com/kakao/khaiii.git
cd khaiii
다음으로 cmake를 설치해주어야 합니다.
pip install cmake

다음으로는 khaiii 설치에 필요한 폴더를 만들어주고 cmake를 실행 지켜줍니다.
mkdir build
cd build
cmake ..
여기까지 완료가 되면 아래 커맨드를 실행시켜 줍니다.
make all
다음으로는 khaiii를 실행시키기 위한 리소스를 빌드해 줍니다.
make resource
위 명령어는 기본적으로 base model를 로드하지만 Large model이 필요하신 분은 다음 명령어를 실행해 줍니다.
make large_resource
다음으로 빌드한 리소스를 설치해 줍니다.
make install
마지막으로 파이썬에 설치하기 위해 패키지를 만들고 파이썬에 설치해 줍니다.
make package_python
cd package_python
pip install .
설치가 정상적으로 되었다면 다음과 같이 실행할 수 있어야 합니다.
from khaiii import KhaiiiApi
api = KhaiiiApi()
for word in api.analyze('안녕하세요? 오늘은 날씨가 좋네요.'):
print(word)
위 코드를 실행시켜 줍니다.

성공적으로 설치가 되었다면 위와 같이 분석한 결과를 보여줍니다.
3. 사용사 정의 사전 추가 방법
3.1. 패키지를 통째로 업데이트하는 방법
형태소 분석을 진행할 때 분석이 제대로 되지 않는 경우가 존재합니다. 예를 들어 최근 뉴스에서 많이 보이는 '슈링크플레이션' 같은 신조어는 제대로 분석이 안 되는 문제점이 존재합니다.

이러한 경우에는 직접 사전에 추가해주어야 합니다.
사용자 사전에 추가하기 위해서는 우선 khaiii가 설치된 폴더로 들어갑니다.
khaiii > rsc > src 순으로 들어가서 preanal.manual 파일을 텍스트 편집기(MacOs)로 열어주면 다음과 같이 나옵니다.

여기에서 추가하고 싶은 단어의 형태소 분석 형태를 추가해 주고 저장해 줍니다. 참고로 사전에 추가할 때는 아래와 같이 형식을 맞춰주어야 합니다. 형식을 맞춰주지 않으면 빌드 과정에서 에러가 발생합니다.
<어절(패턴)> <탭> <분석 결과>
다음으로는 분석 사전이 바뀌었기 때문에 다시 패키지를 빌드해주어야 합니다.
빌드는 khaiii / build 폴더에서 진행합니다.
make resource
make package_python
cd package_python
pip install .
처음 설치할 때와 같은 방식으로 빌드 및 설치를 진행해 줍니다.

설치가 완료되고 다시 실행을 시켜주면 위와 같이 기존 분석과는 다르게 하나의 고유명사로 인식하게 됩니다.
3.2. 빌드만 하고 사전의 경로를 알려주는 방법
만약 매번 빌드하고 패키지 설치가 귀찮으신 분들은 다음과 같은 방법도 있습니다.
이번에는 '비트코인으로 뭘하나요?'를 예로 들어보겠습니다.

사용자사전에 따로 추가하지 않았기 때문에 '비트'와 '코인'이 각각 형태소로 분석되는 모습을 확인할 수 있습니다.
마찬가지로 비트코인을 사용자사전에 추가해 보겠습니다.

다음으로는 이전과 마찬가지로 khaiii/build로 들어가서 아래 명령어를 통해 빌드를 다시 해 줍니다.
make resource
이전에 소개해드렸던 방법은 파이썬 패키지를 만들어서 다시 설치하였지만, 간단히 빌드한 사전을 직접 불러와서 사용할 수도 있습니다.
대신, 사용자 사전이 어디에 있는지를 인자로 전달해주어야 합니다.
from khaiii import KhaiiiApi
#사전의 경로를 인자로 전달하기
api = KhaiiiApi(rsc_dir = './khaiii/build/share/khaiii')
for word in api.analyze('비트코인으로 뭘하나요?'):
print(word)
위와 같이 사전의 경로를 추가해 주고 실행시켜 보면 아래와 같이 하나의 단어로 분석해 주는 모습을 볼 수 있습니다.

Tip 1)
사전파일은 preanal.~로 구분하기 때문에 별도로 이름을 지어서 preanal.my 혹은 preanal.coin 등과 같이 파일을 만들어서 추가해 줘도 무방합니다.

4. Khaiii 사용방법
khaiii에서는 분석 메서드로 'analyze'를 제공합니다. 앞서 테스트에서 볼 수 있듯이, 분석 전과 분석 후의 모습을 다 보여줍니다. 이를 이용해서 분석에 사용할 수도 있지만, 기존 Konlpy와 비슷하게 사용하고자 하면 추가로 구현이 필요해 보입니다.
Konlpy에서 제공하는 형태소 분석기는 nouns, morphs, pos 메서드입니다. 간단히 이 세 가지 메서드를 구현해 보았습니다.
from khaiii import KhaiiiApi
class Khaiii_Util:
def __init__(self):
self.api = KhaiiiApi(rsc_dir = './khaiii/build/share/khaiii')
def khaiii_pos(self,sentence):
result = []
for word in self.api.analyze(sentence):
for i in word.morphs:
result.append((i.lex,i.tag))
return result
def khaiii_nouns(self,sentence):
result = []
for word in self.api.analyze(sentence):
for i in word.morphs:
if i.tag in ['NNG','NNP','NNB','NR','NP']:
result.append(i.lex)
return result
def khaiii_morphs(self,sentence):
result = []
for word in self.api.analyze(sentence):
for i in word.morphs:
result.append(i.lex)
return result
간단히 위와 같이 구현하였으며 기존 Konlpy와 같은 형식의 출력이 될 수 있도록 하였습니다.
이전 포스트와 같은 문장인 '나는 사과를 좋아한다.'라는 문장을 입력으로 넣고 실행시켜 보았습니다.
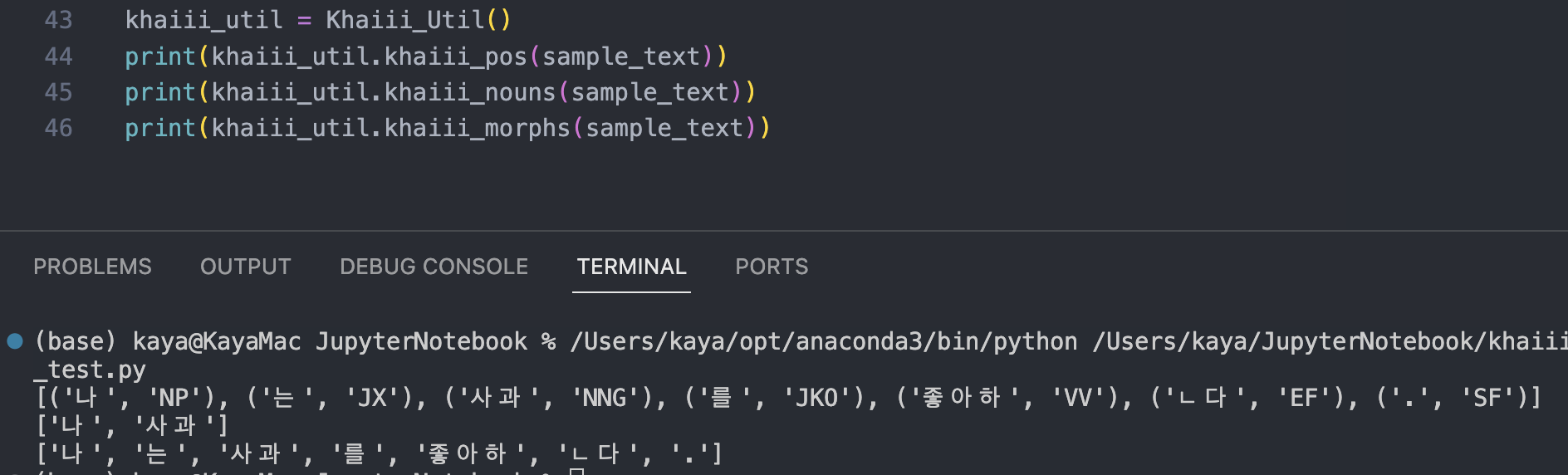
기존 Konlpy에서 보여주는 출력형식과 같음을 확인할 수 있습니다.
Reference
[1] Khaiii(GitHub)
'자연어 처리(NLP) > 전처리(Pre-processing)' 카테고리의 다른 글
| Tokenizer : 기본적인 토큰화(Tokenization) 방법 (0) | 2024.09.26 |
|---|---|
| WordPiece Tokenizer 이해 및 정리 (1) | 2023.12.18 |
| Byte Pair Encoding(BPE) tokenizer 정리 (1) | 2023.12.11 |
| Tokenizer : 한국어 형태소 분석기의 종류와 사용 방법 (2) | 2022.07.26 |



