Overview
이번 포스트에서는 Position encoding에 대해 정리합니다. 'Attention is all you need'에서 제시한 모델인 Transformer에서 사용된 Position encoding은 self-attention이 order independent하기 때문에 모델에게 input token간의 순서를 알려주기 위해 사용되었습니다. 이후 많은 연구에서 기존 position encoding과는 약간 다른 관점에서의 position encoding이 제안되었습니다.
우선, 기존 Transformer 모델에서 활용된 positional encoding의 필요성과 그 개념에 대해 간단히 살펴본 후, T5 저자들이 활용한 relative position encoding에 대해 정리하고자 합니다. T5에서 사용된 relative position encoding은 'Self-Attention With Relative Position Representations'에서 소개된 relative position encoding을 기반으로 하고 있지만, 약간 다르게 활용하였습니다. 마지막으로는 relative position encoding의 한계점에 대해 알아보겠습니다.
Motivation
제가 seqence to sequence 구조하면 가장 먼저 떠오르는 모델은 RNN입니다. RNN은 입력 시퀀스를 순차적으로 입력받게 되며, 입력받은 토큰은 RNN의 hidden state에 함축적으로 표현이 됩니다. 예를들어 '이 수박은 맛있는 수박 입니다' 라는 문장이 있으며, 형태소 분석을 통해 ['이', '수박', '맛있', '수박', '입니다'] 라고 변환되었다고 가정하면, RNN에는 다음과 같이 입력이 됩니다.

처음에 나온 '수박'이라는 단어와 뒤에 나오는 '수박' 이라는 토큰은 같은 '수박'을 뜻하지만, 다음에 와야 하는 단어는 서로 다릅니다.
처음 나오는 '수박' 이라는 토큰 뒤에는 '맛있' 이 나와야하지만, 뒤에 나오는 '수박'의 다음 토큰으로는 '입니다' 가 나와야 합니다. 이처럼 같은 단어가 나와야 할지라도 문장 내 앞 뒤 순서를 고려해야합니다. RNN에서의 두번째 나타나는 '수박'이 입력되는 시점에는 이미 앞에서부터 ['이', '수박', '맛있']이 입력되었으며, 이 정보들이 RNN의 hidden state에 정보가 이미 있기 때문에 앞에 나온 '수박'과 구별됨을 알 수 있습니다.
Position Encoding
Position encoding은 말 그대로 위치 정보를 벡터로 표현하는 것을 의미합니다. 가장 간단한 방법으로는 각 위치를 정수로 표현하는 방법을 생각해볼 수 있습니다. 예를들어 '나는 어제 밥을 먹었다' 라는 문장에 대해 '나는'에는 1을, '어제' 에는 2을, '밥을'에는 3를, 마지막으로 '먹었다' 에는 4이라는 정수로 위치를 표현해줄 수 있습니다. 이 방법은 매우 간단하지만 문장의 길이가 길 수록 위치 정보에 해당하는 숫자가 매우 커지게 되므로 학습 시 문제가 생길 수 있습니다. 그렇다면 문장의 최대 길이를 구해서 Normalize 하는 방법을 생각해 볼 수 있습니다. 예를들어 문장의 최대 길이를 4라고 하면 '나는'에는 0.25이, '어제' 에는 0.5이, '밥을'에는 '0.75'이, '먹었다' 에는 1이 position encoding으로 들어가게 됩니다. 언뜻보면 숫자도 엄청 크지 않고 encoding이 잘 된것 같지만, 한가지 문제가 있습니다. 바로 길이가 다른 문장에 대해서 위치가 다르지만 encoding값이 동일한 경우 입니다. 문장 1 : '나는 어제 밥을 먹었다' 문장 2 : '그가 나와 어제 한 행동은 그녀를 떠나게 만들었다' 라는 문장이 있을 때, 첫번째 문장에서의 '나는'는 0.25(1/4)로 인코딩 되며, 두번째 문장에서의 '나와' 도 0.25(2/8)로 인코딩이 됩니다. 각 문장에서의 위치가 다른데 position encoding값이 같아지는 경우가 생기기 때문에 적절하지 않습니다. 다음에 소개할 transformer에서는 sine함수와 cosine함수를 이용하여 모델에게 위치 정보를 전달하였습니다. sine함수와 cosine함수는 모두 주기함수이며, 모든 값이 -1과 1 사이에 있습니다. 언뜻보면 값이 엄청 크지도 않으며, 매 값이 달라지지만, 특정 부분에서 방금과 같이 같은 값을 갖게 되는 경우 때문에 사용할 수 없을것 같이 느껴지지만, 각 차원마다 주기를 다르게 주는 방식으로 문제를 해결하였습니다.
Transformer : Positional encoding
Transformer에서 대표적인 개념 중 하나는 'self attention' 입니다. 우선 Attention 연산은 Query는 decoder의 입력 부분, 그리고 Key와 Value값은 Encoder에서 입력을 받아서 다음과 같은 연산을 하지만, self attention은 Query,Key,Value가 모두 같은 입력 부분에서 입력이 됩니다.
$$ Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V $$
하나의 Query에 대해서 모든 입력 단어와의 Attention 연산을 하기 때문에 앞뒤 순서가 고려되지 않습니다. 이러한 이유로 self attention은 order independent합니다. 하지만 자연어의 특성 상, 각 토큰의 앞 뒤 순서는 매우 중요한 특징이기 때문에 모델에게 순서 정보를 반드시 전달해주어야 합니다.(앞에 나온 수박과 뒤에 나온 수박은 서로 다른 위치에 있는 수박이다!)
이러한 이유로 일반적으로 self attention을 사용할 때, 순서 정보를 Embedding에 추가합니다. Original Transformer에서는 Sin함수와 Cos함수를 활용하여 순서 정보를 추가하였습니다. 각 position을 정수로 표현하였을 때, 아래와 같은 수식을 활용하였습니다.
$$ PE(pos,2i) = sin(pos / 10000^{2i/d_{model}}) $$
$$ PE(pos,2i+1) = cos(pos / 10000^{2i/d_{model}}) $$
sine만 단독으로 사용하는 경우, 주기함수가 가진 특징으로 인해 특정 위치에서 같은 값을 갖게 되는 경우가 존재합니다. 따라서 주기를 계속 변화시키는 방법으로 \( pos/10000^{2i/d_{model}} \) 을 사용하게 됩니다. 또한 positional encoding의 특성 상 위치가 달라도 토큰거의 거리가 같다면 절대적인 거리는 동일해야 합니다. 즉 \(sin(10) \)과 \(sin(20)\)의 거리와 \(sin(30)\)과 \(sin(40)\)의 거리는 동일해야합니다. 하지만 직접 계산해보면 두 거리는 다릅니다.

하지만 여기에 cosine을 추가하면 달라집니다.
예를들어 10번째,20번째,30번째,40번째의 단어를 position encoding으로 표현하면 다음과 같습니다.

여기에서 이제 10번째 단어와 20번째의 단어의 거리, 그리고 30번째 단어와 40번째 단어 사이의 거리를 구해보면 다음과 같습니다.

전과 마찬가지로 python을 이용하여 구해본 결과 두 결과가 동일합니다. 그 이유는 삼각함수의 덧셈정리를 이용하여 보여줄 수 있습니다. 좀 더 명확하게는 선형변환 중 하나인 회전변환을 이용합니다. 회전변환 행렬은 다음과 같습니다.

이를 적용하면 다음과 같습니다.

따라서 10번째 단어와 30번째 단어는 같은 회전변환을 했다고 볼 수 있습니다. 결과적으로 간격은 같지만 위치가 다른 경우에도 회전변환에 의해 거리는 모두 같음을 알 수 있습니다. 또한 i번째의 위치를 알고 있다면 j번째 위치한 단어의 position encoding값도 구할 수 있습니다. 이러한 이유로 sine 단독으로 사용하지 않고 cosine도 같이 쓰는게 아닐까 싶습니다.
Relative position encoding
relative position encoding은 tranformer에서 사용한 positional encoding과는 다르게 각 단어의 상대적인 위치를 활용합니다. relative position encoding을 제시한 'Self-Attention With Relative Position Representations' 논문에서 저자들은 다음과 같은 가정을 합니다.
"We hypothesized that precise relative position information is not useful beyond a certain distance."
즉 일정 거리이상 떨어져 있는 단어의 상대적인 위치 정보는 그다지 유용하지 않을것이라는 가정을 하였습니다. 저자들은 이러한 가정을 기반으로 일정한 거리값인 \( k \)를 설정하였습니다. \(k\) 이상의 거리에 있는 단어는 모두 \(k\)값 혹은 \(-k\)값으로 위치 인덱스를 통일해줍니다. 이를 저자들은 clipping이라고 칭하며, 논문에서 표현한 수식은 다음과 같습니다.
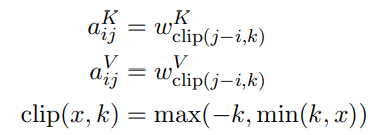
조금 더 이해하기 쉽게 'the dog chased the pig so fast' 라는 문장을 예로 들어보겠습니다. 예를들어 \( k = 3 \)으로 설정하게 되면 다음과 같이 단어와 단어 사이의 위치 관계를 표현할 수 있습니다. 아래 표는 i번째 단어와 j번째 단어의 관계를 숫자로 표현한 테이블입니다.
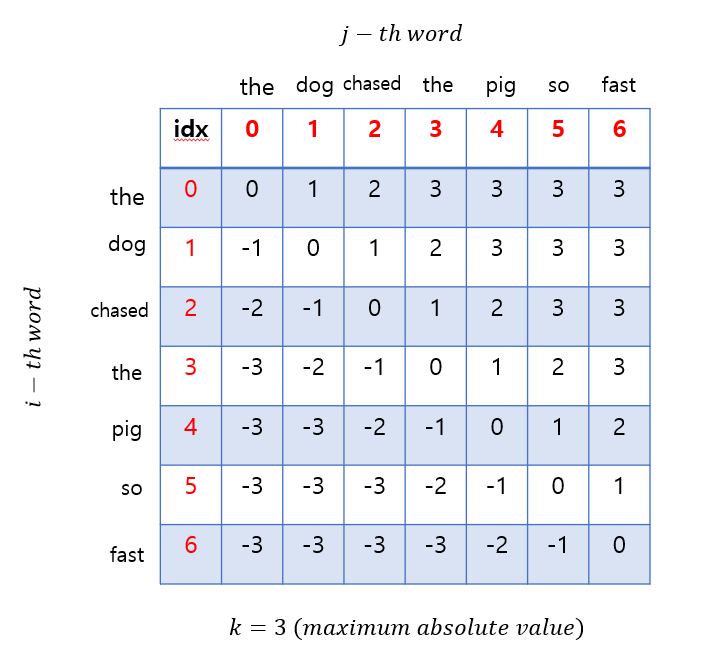
우선 이해하기 쉽게 \(i\) 번째의 위치를 0으로 설정하면 다음과 같이 표현할 수 있습니다. 왼쪽에서 첫번째 나오는 'the'와 바로 옆에 있는 'dog'는 바로 옆에 있으므로 거리가 1이 되므로 1로 표현을 하였습니다. 또한, 'chased'와 'so'는 3만큼 떨어져 있으므로 3으로 표현하였습니다. 하지만, 'chased'와 'fast'의 거리는 4이지만, 현재 설정한 \(k\) 값은 3이기 때문에 4이상 떨어진 단어는 가정에 의해 별로 중요하지 않는다고 판단하여 최대값인 3으로 표현한 모습을 볼 수있습니다. 반대로 'so' 단어 입장에서 보면 왼쪽에 있는 'chased'는 3만큼 떨어져 있지만 왼쪽에 있으므로 -3으로 표현하였습니다. 마찬가지로 'so' 단어 입장에서 'dog'는 4만큼 떨어져 있지만, \(k=3\)으로 설정하였기 때문에 -4가 아닌 -3으로 표현을 한 모습을 볼 수 있습니다. 지금까지 볼 수 있듯이, 어떤 i번째 단어에 대해 모든 단어의 거리를 \([-k,k]\) 사이의 정수값으로 표현하는 모습을 볼 수 있습니다(총 \(2k+1\)개의 정수로 표현).
하지만 실제로 구현을 할 때에는 음수값을 사용하지 않고 0이상의 정수를 표현하는것이 일반적으로 다음과 같이 표현합니다.

기존 단어의 표현이 모두 \([-k,k]\) 사이의 정수 값으로 표현을 하였기 때문에 \(k\)를 더해줌으로써 \([0,2k]\)사이의 정수로 표현을 할 수 있습니다.여기서 6은 i번째 단어에서 오른쪽만큼 \(k\)이상 떨어져있음을 의미하며, 0은 i번째 단어에서 왼쪽으로 \(k\)이상 떨어져있음을 의미합니다.
위의 내용을 코드로 구현하면 다음과 같이 구현해볼 수 있습니다.
def Relative_position_encoding(length_q,length_k,maximum_absolute_value):
range_vec_q = torch.arange(length_q)
range_vec_k = torch.arange(length_k)
distance_matrix = range_vec_k[None,:] - range_vec_q[:,None]
#Clipping
distance_matrix = torch.clamp(distance_matrix,-maximum_absolute_value,maximum_absolute_value)
final_matrix = distance_matrix + maximum_absolute_value
return final_matrix
위 코드를 실행시키면 다음과 같습니다.

앞선 예제와 같은 모습으로 출력되는것을 확인할 수 있습니다.
하지만 위와 같은 숫자를 바로 신경망에 대입할 수는 없습니다.각 위치 정보를 알게되었으니 해당 위치 정보를 학습해서 lookup table형식으로 참고하여 신경망에 전달하는 방식을 사용합니다. 즉, 학습하면 할 수록 relative position embedding값도 같이 변하게 됩니다. 이제 상대적인 위치를 알게 되었으니 이 정보를 이용하여 학습할 수 있도록 embedding table을 만들어주면 됩니다. Relative position encoding에서 사용하는 숫자의 갯수는 \( 2*k+1 \)개 이므로, 이 정보를 이용하여 구현을 해주면 됩니다.
구현하면 다음과 같습니다.
class RelativePosition(nn.Module):
def __init__(self,num_units,max_absolute_value):
#num_units = head_dim
self.max_absolute_value = max_absolute_value
#shape : (2k+1) X embedding_dim
self.embedding_table = nn.Parameter(torch.Tensor(self.max_absolute_value * 2 + 1,num_units))
#initialize : xavier
nn.init.xavier_uniform_(self.embedding_table)
def forward(self,length_q,length_k):
range_vec_q = torch.arange(length_q)
range_vec_k = torch.arange(length_k)
distance_mat = range_vec_k[None,:] - range_vec_q[:,None]
distance_mat_clipped = torch.clamp(distance_mat, -self.max_absolute_value, self.max_absolute_value)
final_mat = distance_mat_clipped + self.max_absolute_value
final_mat = torch.LongTensor(final_mat).cuda()
return self.embedding_table[final_mat].cuda()
우선, 우리가 계속 참고해야하는 embedding table은 모든 relative position encoding의 정보가 다 들어가야하므로 \(2*k + 1\)개의 정보와 각각이 가지고 있어야 하는 embedding dimension 의 크기만큼 값을 초기화해줍니다. 또한 이 값은 학습 중에 업데이트가 계속 되어야 하므로 nn.Parameter를 이용하여 학습할 수 있도록 해주어야 합니다. 이후 forward에서는 처음 예제코드와 동일한 방식으로 값을 맞추어주면 됩니다. 이전 코드와 약간 다른점은 embedding_table[final_mat] 부분인데 해당하는 위치에 있는 embedding table값을 가져오는 것으로 이해하면 됩니다.
실제로 실행시켜보면 다음과 같습니다.

예제의 relative position encoding에서 첫번째 줄이 [3,4,5,6,6,6,6] 이였던것을 기억하시나요? 해당 부분을 인덱스 취급하여 실제로 우리가 사용하는 embedding table에서 해당 줄을 가져온 모습입니다. 보시면 3번째행의 모습을 가져올 수 있으며, 차례대로 4,5,6번째 행을 가져온 모습을 볼 수 있습니다. 또한 이후 값들은 모두 6으로 동일하므로 계속 같은 값을 가져오는 모습을 볼 수 있습니다. 이러한 방식으로 모든 \( i\)번째 단어에 대해 relative position embedding을 수행할 수 있습니다.
이후 신경망에서는 이 값을 word embedding에 더하거나 concat하는 방식으로 활용하여 사용할 수 있습니다.
Limitation : Inefficient computer Memory & Inference Speed
Relative position encoding은 상대적인 위치를 저장하기 위해 look-up table을 이용합니다. 이로 인해 사용하는 look-up table의 크기 만큼 메모리를 사용합니다. relative position encoding은 \( O(LD + L^2) \)의 공간을 사용한다고 합니다.
실제로 다른 position encoding과의 비교를 한 연구 중, 'Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation' 에서 비교한 그래프입니다. Relative position encoding을 활용하는 모델로 T5 모델을 예로 들 수 있습니다.

논문에서는 Word per second(WPS) 지표를 이용하여 각각의 encoding 방법별 처리속도를 비교하였습니다. 값이 클수록 시간당 처리하는 단어의 수가 많으므로 빠르다고 볼 수 있습니다. Sinusoidal은 제일 처음에 봤던 sine과 cosine을 이용한 Transformer 모델에서 사용한 positional encoding입니다. 간단히 Sinusodial(Absolute position encoding) 과 T5(Relative position encoding)의 각각의 지표만 비교해보아도 T5에서 활용한 relative position encoding이 training speed,inference speed도 느리며, 메모리는 오히려 더 먹는 비효율적인 모습을 보여주고 있습니다. 이러한 비효율적인 면으로 인해 실제로는 잘 사용하지는 않는다고 합니다.
'자연어 처리(NLP) > 모델(Model)' 카테고리의 다른 글
| RoBERTa : A Robustly Optimized BERT Pretraining Approach 정리 및 이해 (0) | 2024.03.07 |
|---|---|
| BERT(Bidirectional Encoder Representations from Transformers) 개념 정리 및 이해 (0) | 2024.02.17 |
| RNN/LSTM/GRU 의 구조를 이해해보자 (0) | 2022.11.08 |
| Transformer를 이용한 번역모델 구축 (4) | 2022.01.22 |
| Transformer를 이해하고 구현해보자! (2) (0) | 2022.01.21 |



