이전글 1 : Transformer를 이해하고 구현해보자! (1)
이전글 2 : Transformer를 이해하고 구현해보자! (2)
이번 포스팅에서는 이전에 구현한 모델을 이용하여 간단히 한-영 번역기를 만들어 보도록 하겠습니다.
전체 코드를 보고 싶으신 분은 아래 깃허브를 참고해주세요.
Github Link : (정리되면 링크 업로드 예정입니다!)
1. Data
데이터는 AI-Hub에서 공개한 '한국어-영어(병렬) 말뭉치' 데이터를 사용하였습니다.
해당 사이트에 회원가입을 진행 한 후, 전체 160만쌍의 데이터를 다운 받을 수도 있지만,
본 포스트에서는 오직 '샘플 데이터' 만 사용하였습니다.

샘플 데이터에 대해 간단히 요약하면 다음과 같습니다.
샘플 데이터는 총 6개의 파일로 구성되어 있으며 각각 다른 문체로 이루어져 있습니다.

샘플 데이터마다 각각 다른 속성을 가지고 있지만, 우리가 필요한 부분은 단순히 번역 모델에 사용할 한국어-영어 병렬 말뭉치 뿐이므로 각 데이터에서 한국어-영어 부분만 가져왔습니다.
아래 표는 각 파일에서 한국어-영어 부분만 추출한 데이터 중 일부입니다.

다음으로 sklearn에서 제공하는 train_test_split을 이용하여 Train data,Validation data, Test data 으로 나누어 주었으며, 각 데이터의 비율은 7 : 1.2 : 1.8 로 나누었습니다.
나눈 데이터의 갯수는 다음과 같습니다.
| 종류 | 갯수(Count) |
| Train data | 46383 |
| Validation data | 7951 |
| Test data | 11928 |
| Total | 66262 |
아래 코드는 학습 데이터를 만들때 사용한 코드입니다!
import pandas as pd
import os
from sklearn.model_selection import train_test_split
file_path = "./data/original/"
file_list= ['1_구어체_190920.xlsx','2_대화체_190920.xlsx','3_문어체_뉴스_190920.xlsx','4_문어체_한국문화_190920.xlsx', '5_문어체_조례_190920.xlsx','6_문어체_지자체웹사이트_190920.xlsx']
#or use os.listdir
#1
file_1 = pd.read_excel(file_path + file_list[0])
kor_1 = file_1['한국어']
eng_1 = file_1["영어 검수"]
#2.
file_2 = pd.read_excel(file_path + file_list[1])
kor_2 = file_2['한국어']
eng_2 = file_2['영어검수']
#3.
file_3 = pd.read_excel(file_path + file_list[2])
kor_3 = file_3['원문']
eng_3 = file_3['REVIEW']
#4~6
kor_46 = pd.Series()
eng_46 = pd.Series()
for name in file_list[3:]:
files = pd.read_excel(file_path + name)
kor_46 = pd.concat([kor_46,files['원문']])
eng_46 = pd.concat([eng_46,files['Review']])
kor_total = pd.concat([kor_1,kor_2,kor_3,kor_46])
eng_total = pd.concat([eng_1,eng_2,eng_3,eng_46])
total = pd.DataFrame({"kor" : kor_total,"eng" : eng_total})
print(total.head())
#split data
train,test= train_test_split(total,test_size = 0.3)
valid,test = train_test_split(test,test_size = 0.6)
print("train_data size : ",len(train))
print("valid_data size : ",len(valid))
print("test_data size : ",len(test))
train.to_csv("./data/train.csv",encoding = 'utf-8',index = False)
valid.to_csv("./data/valid.csv",encoding = 'utf-8',index = False)
test.to_csv("./data/test.csv",encoding = 'utf-8',index = False)2. Load data
데이터가 준비되었으면 다음으로 해야 할 일은 모델에 집어넣을 수 있게 준비를 하는것 입니다.
저는 torchtext를 이용하였으므로, torchtext 기준으로 말씀드리겠습니다.
우선, torchtext에서 제공하는 Field를 이용하여 다음과 같이 Encoder와 Decoder에 들어갈 데이터 필드를 정의하였습니다.
kor_text = data.Field(fix_length=50,sequential= True,batch_first= True,tokenize=tokenizer.morphs)
eng_text = data.Field(fix_length=50,sequential= True,batch_first= True,tokenize=str.split,lower= True,init_token="<sos>",eos_token="<eos>")필드에 들어가는 파라메터들의 의미들은 torchtext document(클릭) 에서 확인해보시기 바랍니다!
입력 텍스트에 대해서 Tokenizer를 이용하여 각 문장을 토큰화 해 주어야 합니다.
저 같은 경우는 간단히 한국어에 대해서는 tokenizer로 Mecab 을 사용하였으며, 영어 데이터는 단순히 띄어쓰기 기준으로 split을 적용하였습니다. (물론 다른 Tokenizer를 적용해볼 수 있습니다!)
그리고 영어 텍스트는 Decoder에 들어가게 되는데, 이때 Special Token을 추가해 주었습니다.
Decoder의 입력에서 첫번째 값은 문장이 시작한다는 뜻의 '<sos>' token(Start of sentence)을 넣어주었으며, 각 문장의 끝을 알리는 '<eos>' token(End of sentence)를 넣어주었으며, Padding을 의미하는 '<pad>' token은 기본값으로 들어가기 때문에 따로 입력하지는 않았습니다.
따라서 Decoder에 들어가는 문장은 다음과 같이 바뀌게 됩니다.

다음으로는 이전에 저장했던 실제 데이터 파일을 불러와서 앞서 정의한 Field에 적용시켜 주면 됩니다!
#데이터 불러오기
train_data,valid_data,test_data = data.TabularDataset.splits(
path = './data/',
train = 'train.csv',validation='valid.csv',test = 'test.csv',
format = 'csv',
fields = field,
skip_header = True
)
#Field 적용
kor_text.build_vocab(train_data)
eng_text.build_vocab(train_data
#print special tokens
print("kor <pad>token id : ",kor_text.vocab.stoi['<pad>'])
print("eng <pad>token id : ",eng_text.vocab.stoi['<pad>'])
print("eng <eos>token id : ",eng_text.vocab.stoi['<eos>'])
print("eng <sos>token id : ",eng_text.vocab.stoi['<sos>'])다음으로는 Iterator를 이용하여 batch_size별로 데이터를 모델에 넣을 수 있도록 나눠줍니다.
저같은 경우는 batch_size = 32로 지정하였습니다.
train_loader = Iterator(dataset = train_data, batch_size = batch_size)
valid_loader = Iterator(dataset = valid_data, batch_size = batch_size)
test_loader = Iterator(dataset = test_data,batch_size = batch_size)데이터가 잘 적용됐나 보려면 다음과 같이 하나의 샘플을 꺼내서 텐서 형태로 볼 수 있습니다.
#one sample
batch = next(iter(train_loader))
print(batch.kor)
print(batch.eng)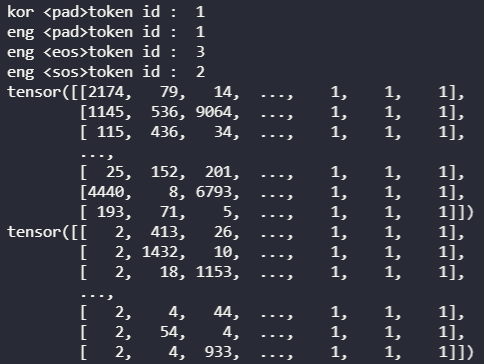
결과를 보시면 위에 있는 tensor는 Train data중 하나의 한국어 데이터 batch 샘플이며, 아래 있는 tensor는 영어 데이터를 나타냅니다.
아까 Decoder에 넣을 문장은 맨 앞에 <sos>, 맨 끝에는 <eos> 넣고, 나머지 부분은 <pad>로 채운다는걸 기억하시나요?
아래 tensor를 보시면 모든 문장의 제일 첫번째 token id가 <sos>를 뜻하는 2로 되어 있는것을 확인 할 수 있으며, 나머지 뒷 부분은 padding이 적용되어 있는 모습을 확인 할 수 있습니다.
3. Model training
이제 데이터도 준비 되었으니 학습을 해 볼 차례입니다.
저는 아래 코드를 이용하여 학습을 진행하였습니다. 코드의 길이가 길어서 자세한 코드는 제 깃허브를 참고해주시기 바랍니다!
def train(model,train_data,optimizer,device,epoch):
#set model to train
model.train()
total_loss = 0
for idx,batch in enumerate(train_data):
src = batch.kor
trg = batch.eng
src = src.to(device)
trg = trg.to(device)
out = model(src,trg[:,:-1]) #output shape : [batch_size,trg_len -1,output_dim]
trg = trg[:,1:].contiguous().view(-1)
out = out.contiguous().view(-1,out.shape[-1])
loss = loss_fn(out,trg) #만약 작동이 안되면 out = out.long(),trg = trg.float()를 시도해볼것.
optimizer.zero_grad()
loss.backward()
#gradient clipping
torch.nn.utils.clip_grad_norm_(model.parameters(),1)
optimizer.step()
total_loss += loss.item()
if idx % 450 == 0 :
print(f"Epoch : {epoch} | Step :{idx}/{len(train_data)} | loss : {loss.item()}")
return total_loss / len(train_data)추가로 제가 학습에 적용한 파라메터들은 다음과 같습니다.
d_model : 512
n_head = 8
max_len = 50
ffn_hidden = 128
n_layers = 6
drop_prob = 0.25
epoch = 100
batch_size = 32
학습에 사용한 loss function은 CrossEntropyLoss를 사용하였습니다. 그리고 Optimizer는 AdamW를 사용하였으며 learning_rate는 5e-4로 설정하였습니다.
*max_len은 학습에 사용할 텍스트 데이터의 평균 길이를 구해서 적당히 본인이 지정하면 됩니다!
4. Experimental Result
학습에 대한 평가 지표로는 BLEU score를 적용하였습니다.
실험은 총 4번 진행하였으며, 각 실험 환경은 아래와 같습니다.
1. 실험 3번 진행
- OS : Linux Ubuntu 20.04 LTS
- Python Version : 3.8.5
- GPU : RTX 3080
2. 실험 1번 진행
- OS : Window 11
- Python Version : 3.7.6
- GPU : RTX 2060 Super
위 환경으로 실험한 결과는 다음과 같이 나왔습니다.
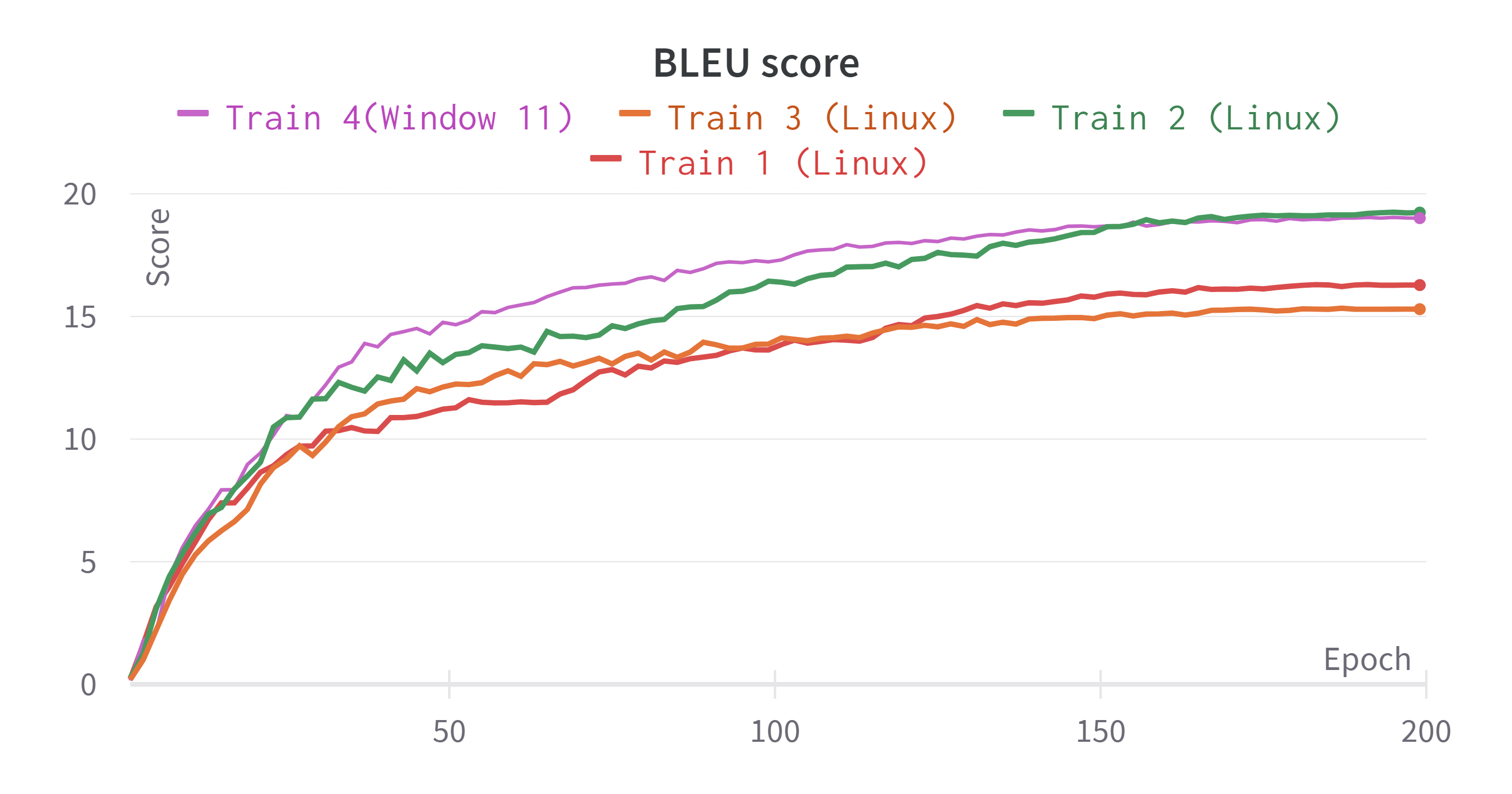
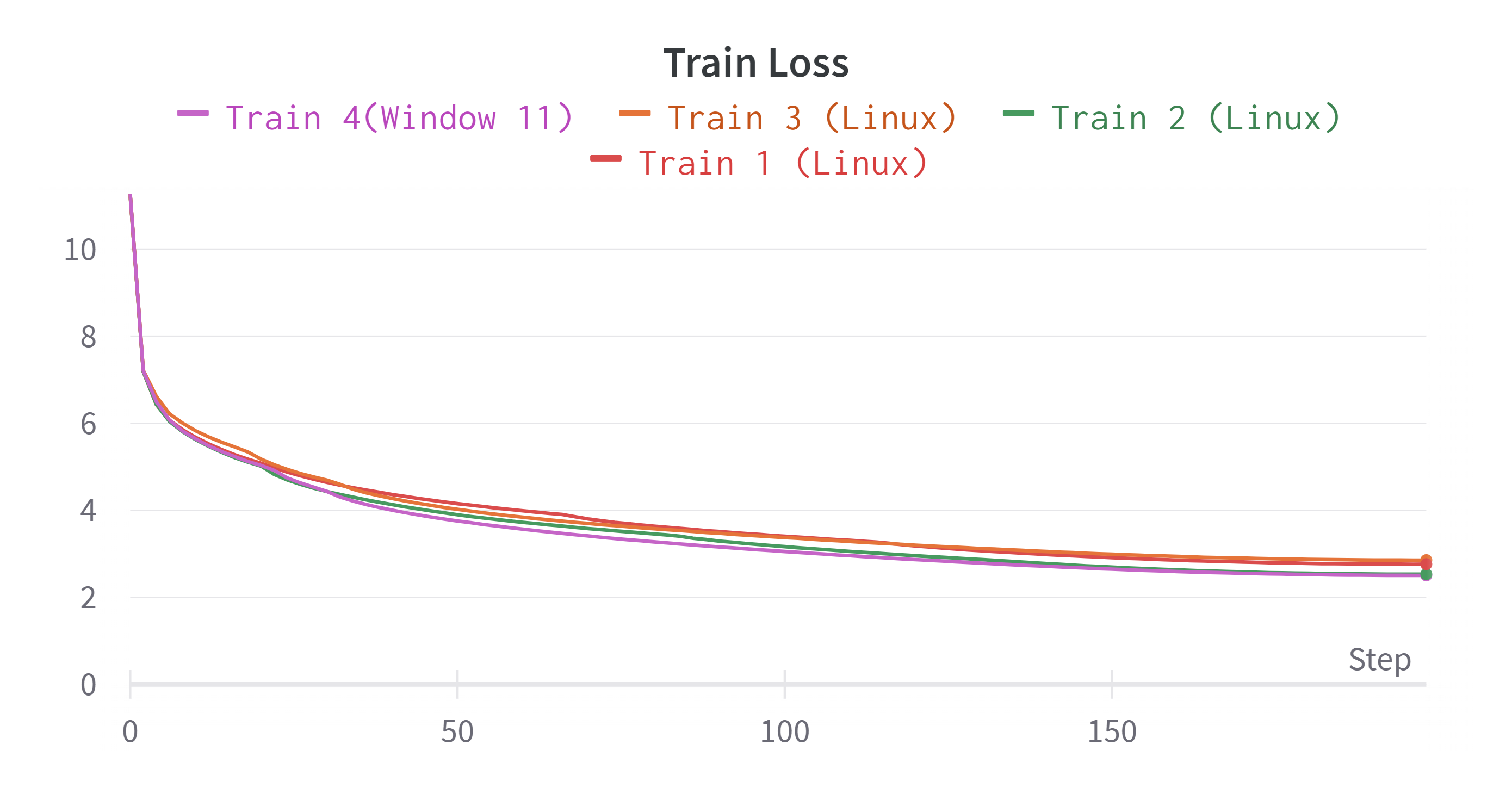
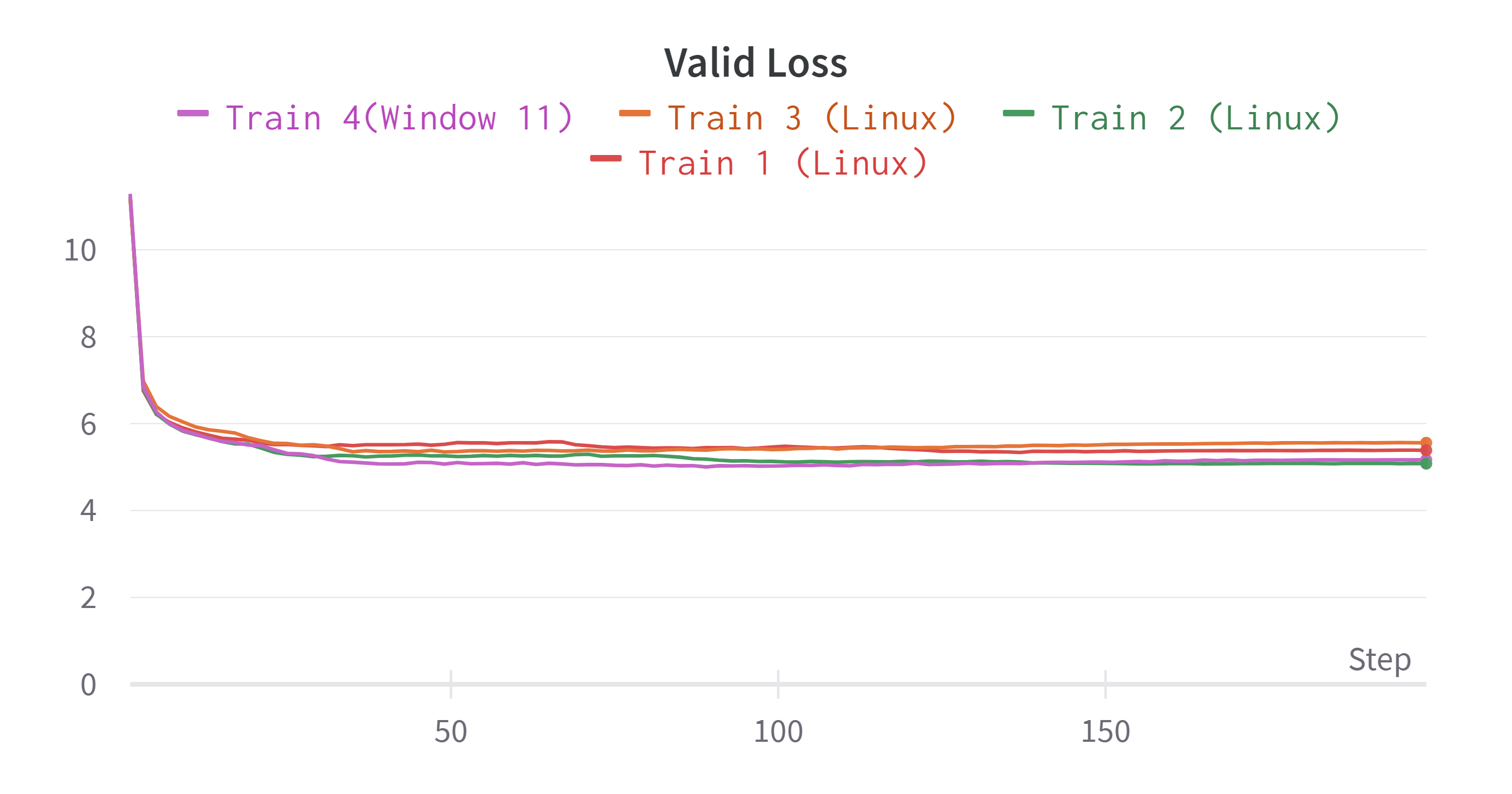
실험 결과 보려고 Weight&Bias를 이용했는데 데이터 포인트가 1,3,5,7,9,...이런식으로 잡혀서 Epoch는 100인데 200까지 표가 그려졌습니다...ㅜㅜ 보시는데 참고해주시기 바랍니다.
뭐 어쨋든!
4번의 실험 모두 100 Epoch으로 설정해두고 실험을 진행하였습니다.
각 Train별 Best Score와 최종 Loss를 정리하면 다음과 같습니다.
| Experiments | Train Loss | Validation Loss | BLEU Score |
| Train 1 (Linux) | 2.761 | 5.386 | 16.279 |
| Train 2 (Linux) | 2.532 | 5.08 | 19.235(BEST) |
| Train 3 (Linux) | 2.854 | 5.558 | 15.296 |
| Train 4 (Window 11) | 2.503 | 5.169 | 19.009 |
가장 높은 BLEU score는 19.235점이 나왔습니다. 본 실험에서 학습에 사용한 데이터가 약 4만7천개 정도 밖에 안되는 적은 양이기 때문에 이러한 결과가 나오지 않았나 생각합니다.
학습 환경이 더 나으신 분들은 한번 더 많은 훈련 데이터로 학습 해보시는걸 추천드립니다.
실험 결과에 차이가 나는 이유는 제 나름대로 분석해본 결과 2가지 이유를 생각해 볼 수 있었습니다.
(1). Learning rate scheduler : 실험 중간에 성능을 조금이라도 높이겠다고 Learning rate scheduler를 적용한적이 있었습니다...
실험에 적용한 스케쥴러는 CosineAnnealingWarmUpRestarts를 적용하였는데, 파라메터 설정이 좀 잘못되었는지 오히려 려 학습이 잘 안된것 같습니다.
(2). 초기값 문제 : 사실 초기값을 따로 설정하지 않았습니다. 이로 인해 실험 결과에 약간의 차이가 발생하는듯 합니다.
+) 추가로 100 Epoch 기준 각 실험별 Running Time은 다음과 같습니다.
| Experiments | GPU | Running Time |
| Train 1 (Linux) | RTX 3080 | 4h 29m 27s |
| Train 2 (Linux) | RTX 3080 | 4h 27m 31s(BEST) |
| Train 3 (Linux) | RTX 3080 | 5h 24m 23s |
| Train 4 (Window 11) | RTX 2060 Super | 9h 59m 30s(WORST) |
다시한번 GPU의 중요성을 깨닫게 되었습니다...
5. Future work
사실 추가로 문장을 입력하면 번역된 문장을 출력해서 볼 수 있게 구현하려고 하였습니다...
하지만 제가 최근에 좀 바빠서 거기까진 구현을 아직 못했습니다..ㅜㅜ
구현되는대로 깃허브와 함께 추가할 예정입니다..!!
6. 후기
지금까지 Transformer를 직접 만들어보고 직접 데이터를 가져와서 모델 학습도 해 보았습니다.
제 생각보다는 모델의 성능이 좋지 못해서 아쉬웠습니다만은 구현하는 내내 재미있었습니다.
물론 Transformers같은 라이브러리에서 모델을 가져와서 학습을 해 볼 수도 있겠습니다만은 직접 한번 구현해보는것도 정말 좋다고 생각합니다.
이 글을 읽어주시는 여러분들도 혹시 시간이 괜찮으시면 직접 한번 구현해보시는걸 추천드립니다!
다음 포스팅에서는 Transformer에서 파생된 모델 중 대표적인 모델인 BERT와 GPT에 대해 각각 알아보도록 하겠습니다!
그 후에는 변형모델 및 특정 Task위주로 글을 쓸 계획입니다.
*잘못된 부분에 대한 지적 및 질문은 언제나 환영입니다!
Github에 업로드 하는대로 링크 추가하겠습니다!
긴 글 읽어주셔서 정말 감사합니다.
'자연어 처리(NLP) > 모델(Model)' 카테고리의 다른 글
| Positional encoding과 Relative position representation은 어떻게 동작하는가 (0) | 2023.10.11 |
|---|---|
| RNN/LSTM/GRU 의 구조를 이해해보자 (0) | 2022.11.08 |
| Transformer를 이해하고 구현해보자! (2) (0) | 2022.01.21 |
| Transformer를 이해하고 구현해보자! (1) (7) | 2021.10.25 |
| [Pytorch] CNN을 이용한 문장 분류 모델 구현하기 (4) | 2021.08.12 |



