#1. Introduction
이번 포스트에서는 CNN에 대해 설명드리려고 합니다.
CNN은 이미지 처리나 음성인식등의 분야에서 널리 쓰이는 기법입니다.
기존의 DNN같은 경우엔 Fully-connected된 계층을 사용하였지만, CNN같은 경우엔 Convolution layer(합성곱 계층)과 pooling layer(풀링 계층)이 추가되는것이 특징입니다.
아래 예시는 일반적인 CNN의 구조를 나타내고 있습니다.(중간에 Activation은 생략되었습니다.)
그림을 살펴보면 Convolution layer와 Pooling layer가 한세트로 묶여서 여러번 층을 구성한것을 확인할 수 있으며, 마지막으로는 Fully connected layer로 마무리하는 구조입니다.

그렇다면 Convolution 계층은 무엇이고 Pooling 계층은 무엇일까? DNN과는 어떤 차이점으로 인해 이미지처리나 음성인식등에 널리 사용되는것일까?
우선 Convolution계층과 Pooling계층이 무엇인지부터 알아보겠습니다.
#2. Convolution Layer
앞서 CNN은 이미지 처리나 음성인식등에서 널리 쓰인다고 하였습니다. 특히 이미지같은 경우엔 가로/세로의 형태가 있는 데이터입니다. 즉, 각 픽셀이 어디에 위치하는지가 중요한 정보가 될 수 있습니다. DNN같은 경우에는 일렬로 세워서 학습데이터에 사용하기 때문에 이러한 위치정보가 없어지는데 CNN은 위치정보를 반영함으로써 데이터의 정보를 더 잘 학습시킬 수 있습니다.
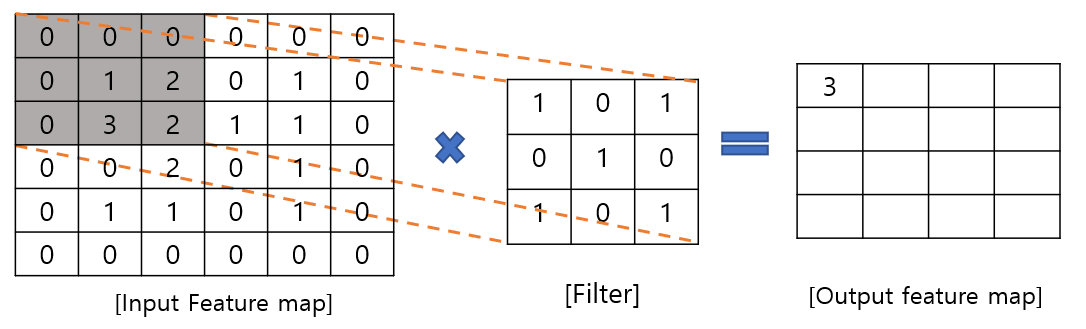
Convolution 계층은 간단하게 말하면 input feature map과 filter의 element wise한 곱으로 나타낼 수 있습니다.
구체적으로는 아래 그림과 같습니다.

위 그림에서 Convolution부분은 다음과 같은 연산이 일어납니다.

CNN에서는 Convolution layer의 input / output값을 Feature map이라고 표현합니다. 여기서는 구별하기위해 input과 output을 모두 적었습니다.
Convolution Layer에서는 input에 대해 filter를 적용하여 convolution 연산을 수행합니다. 즉 [그림3]에서의 회색부분과 Filter에서 같은 위치에 있는 값들끼리 곱해주고 다 더하는 형식의 계산입니다.
즉, 위에 예시는 1*1 + 2*0 + 0*1 + 3*0 + 2*1 + 1*0 + 0*2 + 2*0 + 0*1 = 3 이라는 연산을 수행한것을 나타냅니다.
이렇게 한번 계산하고 끝이 아니고 옆으로 이동하여 차례대로 계산하고 끝까지 가면 다시 왼쪽으로 와서 아래로 움직이고 계산하는데, 이때 움직이는 거리를 Stride(스트라이드)라고 합니다. 즉, 얼마나 건너뛰면서 Convolution연산을 수행할것인지 결정하는것입니다.
위의 예시는 Stride가 최대 1로 설정할 수 없을것처럼 보입니다. 하지만 Padding(패딩)이라는 개념을 적용하면 조금 이야기가 다릅니다. Padding이란 입력데이터(Input Feature map) 주변을 특정값(예를들어 0)으로 채우는 방법입니다.(Zero-padding이라고도 불립니다.) 즉, 위의 예시에 Padding을 적용하면 다음과 같습니다.
Padding을 적용하면 위와같이 Input Feature map의 크기가 커지는 효과를 얻을 수 있습니다. 또한 Input의 크기가 커짐에 따라 Output의 크기 또한 커짐을 볼 수 있습니다. 이렇게 Padding을 적용하면, Output의 크기를 조절할 수 있게 됩니다.
Padding을 적용하는 사례도 있지만, 반대로 적용하지 않는 사례도 존재합니다. Padding을 적용하려는 목적이 도대체 뭘까요?
첫번째로, Padding은 output의 크기를 조절할 수 있습니다.
CNN의 특성상 여러 convolution layer을 거치게 됩니다. 이때, 모든 Layer가 Padding을 적용했다고 가정하면, Output의 크기가 점점 작아짐에 따라 극단적으로 생각하면 나중엔 1X1 사이즈가 나올수도 있습니다.(Input Feature map의 크기 = Filter의 크기) 그렇게 되면 다음 Layer에서 Convolution을 적용할 수 없게 됩니다. 이런 이유로 Padding을 적용하여 Output의 크기를 유지하도록 해 줍니다.
두번째로, Padding을 사용함으로써 가장 가장자리의 데이터손실을 줄일 수 있습니다.
만약, Padding을 사용하지 않는다면, 학습을 진행하면 진행할수록(Convolution layer을 지날수록) 데이터의 크기가 점점 작아지게 됩니다. 즉, 가장자리의 정보가 점점 사라지게 됩니다. 따라서 Padding을 사용함으로써 input과 output의 크기를 맞추어 가장자리의 정보를 잃지 않기 위해서 사용합니다.
Convolution Layer을 거칠때, Convolution 연산과 Stride, Padding을 적용하게 되면 셋 모두 Output의 크기가 달라지는것을 확인할 수 있습니다. 그렇다면, 최종적으로 Convolution layer을 거친 output의 크기는 어떻게 될까요?
Output의 크기는 다음과 같이 정리할 수 있습니다.
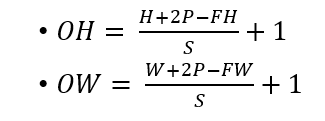
여기서 (OH,OW)는 Output의 size이고, (H,W)는 input size, (FH,FW)는 filter size, P는 Padding size , S는 Stride size입니다.
예를들어 100X100짜리의 사진을 넣는다고 하고, Stride를 2, Padding을 1이라고 하고 Filter의 크기를 4X4이라고 하면 다음과 같이 계산됩니다.

즉, Layer을 한번 거치게 되면 100X100 크기의 사진은 47 X 47로 줄어들게 됩니다.
여기서 주의해야할 점은 만약 분수가 나누어떨어지지 않는다면 결과적으로 크기가 소수점이 되어서 에러를 발생시키게 됩니다.
일반적으로 CNN에서는 Convolution layer에서는 input과 output의 size를 동일하게 유지시켜주고, 다음에 언급할 Pooling Layer에서 Down Sampling을 맡게 한다고 합니다. 만약, 여러분의 모델에 Pooling을 넣지 않는다고 한다면, Convolution layer에서 Down Sampling을 해야할지도 모릅니다.
#3. Pooling Layer
일반적으로 CNN에서 Convolution Layer을 거치고 나면 Pooling Layer로 나오게 됩니다.
그렇다면 Pooling Layer은 무엇이고 Network에서 어떤 역할을 하는걸까요?
1.Pooling Layer은 무엇인가?
Pooling Layer은 가로/세로 방향의 공간을 줄이는 연산입니다. 그림으로 보면 다음과 같습니다.

Pooling은 보시다시피 매우 간단합니다!
Pooling의 종류는 대표적으로 Max Pooling 과 Mean Pooling이 있습니다. Max Pooling은 주어진 영역에서 최대값을 Output으로 설정하는 방법이고, Mean Pooling은 주어진 영역의 값들의 평균을 Output으로 설정하는 방법입니다.
(과거에는 Mean Pooling 방법을 많이 사용하였으나, 최근에는 성능상의 이유로 인해 Max Pooling을 더 많이 사용한다고 합니다.)
즉, 위의 [그림5]의 예시는 Max Pooling 방법이라고 할 수 있습니다.
2.Pooling Layer의 특징은 무엇이고 왜 필요한가?
Pooling layer의 특징은 다음과 같이 정리할 수 있습니다.[밑바닥부터 시작하는 딥러닝 책을 참고하였습니다]
-Pooling layer은 단순히 일정 범위에서 최대값(혹은 평균값)을 구하는 연산이기때문에, 학습을 진행할 매개변수가 없다는점이 있습니다.
-채널수가 변하지 않습니다. 즉, Input Feature map의 채널수와 pooling layer을 거친 Output Feature map의 채널수는 같습니다.
-입력의 변화에 결과값이 잘 변하지 않습니다. 예를들어, Max pooling을 적용하였다고 하면, 최대값이 변하지 않는이상 최대값보다 작은 값들은 아무리 변해도 Pooling의 결과는 그대로 입니다.
그렇다면 pooling을 하면 어떤 좋은점이 있길래 Pooling을 적용하는것일까요?
Pooling을 적용하게되면, 영역 내의 값이 조금 달라진다고 하여도 Max값만 바뀌지 않으면 Output은 동일합니다. 즉, 원본 사진 상단에 사람의 얼굴을 찾는 특징이 있다고 하였을때, 이 사람의 얼굴의 위치가 조금 바뀌어도 유연하게 대처할 수 있다는 뜻입니다.(Pooling의 세번째 특징과 연관이 있다고도 할 수 있을것 같네요)
#4. Q&A : 한번쯤 생각해볼만한 질문
Q1) stride를 넓게 잡는거랑 좁게 잡는거는 어떤 차이가 있을까?
Q2) 마지막에 Affine계층을 추가하는 이유?
Q3) CNN에서 Filter의 갯수를 늘리는것과 Conv layer을 계속 쌓는다는것의 의미?
Q4) filter의 크기는 어떻게 정할까?
Q5) 시계열 데이터도 CNN을 처리할 수 있을까?
Q6) Pooling 대신에 interpolation을 사용하면 어떨까?
#5. CNN 구현해보기
대략적인 CNN에 대한 이해가 되었으면, 이제 직접 구현해 볼 차례입니다!
CNN을 이용하여 문장 분류 모델을 만들어봅시다!
https://kaya-dev.tistory.com/6
[Pytorch] CNN을 이용한 문장 분류 모델 구현하기
이전 포스트에 설명한 CNN을 기반으로, 이번엔 직접 데이터 전처리부터 시작해서 CNN을 이용한 문장 분류까지의 이야기를 해보려고 합니다! 데이터는 한글 데이터 중 널리 알려진 "네이버 영화 리
kaya-dev.tistory.com
#6. Reference & Source
[1] [그림1] Convolution Net(link)
A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way
Artificial Intelligence has been witnessing a monumental growth in bridging the gap between the capabilities of humans and machines…
towardsdatascience.com
[2] [그림2] Convolution Network(link)
https://www.invasivecode.com/weblog/convolutional-neural-networks-ios-10-macos-sierra/
Convolutional Neural Networks in iOS and macOS - iOS Development
In iOS 10 and macOS 10.12, Apple introduces new Convolutional Neural Network APIs in the Metal Performance Shaders Framework and the Accelerate Framework. In a previous post, I already provided you with an introduction on Machine Learning (ML) and Artifici
www.invasivecode.com
[3] 밑바닥부터 시작하는 딥러닝
#7. 참고하면 좋은 사이트
1.
https://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html
ConvNetJS CIFAR-10 demo
cs.stanford.edu
2.
https://ieeexplore.ieee.org/abstract/document/8308186
Understanding of a convolutional neural network
The term Deep Learning or Deep Neural Network refers to Artificial Neural Networks (ANN) with multi layers. Over the last few decades, it has been considered to be one of the most powerful tools, and has become very popular in the literature as it is able
ieeexplore.ieee.org
'자연어 처리(NLP) > 모델(Model)' 카테고리의 다른 글
| RNN/LSTM/GRU 의 구조를 이해해보자 (0) | 2022.11.08 |
|---|---|
| Transformer를 이용한 번역모델 구축 (4) | 2022.01.22 |
| Transformer를 이해하고 구현해보자! (2) (0) | 2022.01.21 |
| Transformer를 이해하고 구현해보자! (1) (7) | 2021.10.25 |
| [Pytorch] CNN을 이용한 문장 분류 모델 구현하기 (4) | 2021.08.12 |



