이전 포스트에 설명한 CNN을 기반으로, 이번엔 직접 데이터 전처리부터 시작해서
CNN을 이용한 문장 분류까지의 이야기를 해보려고 합니다!
데이터는 한글 데이터 중 널리 알려진 "네이버 영화 리뷰"를 사용합니다!
<참고 사항!!>
우선 제가 구현한 컴퓨터의 라이브러리 버전들은 다음과 같습니다.
OS : Linux Ubuntu 20.04 LTS
python = 3.8.5
pytorch = 1.8.0
torchtext = 0.9.0
#Step 1. 데이터 다운받기
'네이버 영화 리뷰' 데이터는 https://github.com/e9t/nsmc/ 에서 다운받을 수 있습니다!

다운 받으시면 모델 훈련에 사용할 'ratings_train.txt' 파일과 모델 테스트에 사용할 'ratings_test.txt' 를 보실 수 있습니다.
이제 다운받은 파일을 이용하여 전처리를 수행해봅시다!
#Step 2-1. 데이터 전처리
아래 구현되어있는 preprocessing.py 에서는 간단한 전처리를 수행합니다.
- 중복 데이터 제거
- nan 데이터 제거
- 한글 필터링
####################
##preprocessing.py##
####################
import pandas as pd
import re
from tqdm import tqdm
from sklearn.model_selection import train_test_split
#Read table
'''
훈련 데이터와 테스트 데이터를 각각 나눠줍니다.
'''
train_data = pd.read_table("ratings_train.txt")
test_data = pd.read_table("ratings_test.txt")
#각 데이터의 갯수
before_train = len(train_data)
before_test = len(test_data)
#Define text cleaning method
def cleaning(text):
#text에서 한글을 제외한 모든 문자열을 공백으로 처리해줍니다.
text = re.sub("[^가-힣ㄱ-ㅎㅏ-ㅣ]"," ",text)
#단어와 단어 사이에 공백이 너무 많아지므로("가나...다!" -> "가나 다 ")
#split후 단어와 단어 사이에 공백이 하나만 들어갈 수 있도록 join을 사용해줍니다.
text = " ".join(text.split())
return text
print("[train]preprocessing...")
#중복 text를 제거해줍니다.
train_data.drop_duplicates(subset = ["document"],inplace = True)
#nan값을 제거해줍니다. (nan값이 있으면 해당 행 자체를 삭제합니다.)
train_data = train_data.dropna(axis = 0)
#cleaning함수 적용
'''
중복과 nan값을 제거한 뒤 남은 text를 이용하여 위에서 정의한 cleaning함수를 사용하여
한글만 남을 수 있도록 처리해줍니다.
'''
print("[train]cleaning...")
train_data['document'] = [cleaning(t) for t in tqdm(train_data['document'])]
#중복과 nan값을 한번 더 제거해줍니다.
'''
이모티콘 및 숫자로만 이루어진 데이터의 경우, cleaning함수를 적용하게 되면 빈 텍스트만 남게 되며
cleaning을 한 이후에 중복이 있을 수 있으므로 중복을 제거해준 뒤,
비어있는 값들에 대해서는 nan 처리를 다시 해줍니다.
'''
train_data.drop_duplicates(subset = ['document'],inplace = True)
train_data = train_data.dropna(axis = 0)
print("[train]done!")
#테스트 데이터에 대해서도 훈련데이터에서 했던것과 마찬가지로 같은 작업을 수행해줍니다.
test_data.drop_duplicates(subset=['document'],inplace = True)
test_data = test_data.dropna(axis = 0)
test_data['document'] = [cleaning(t) for t in test_data['document']]
test_data.drop_duplicates(subset = ['document'],inplace = True)
test_data = test_data.dropna(axis = 0)
#전처리 후, 데이터의 갯수 구하기
after_train = len(train_data)
after_test = len(test_data)
#최종적으로 우리가 사용할 수 있는 데이터의 양을 나타내 줍니다.(전/후 비교)
print("=== 전처리 전 ===")
print('훈련 데이터의 갯수 : %d | 테스트 데이터의 갯수 : %d'%(before_train,before_test))
print("=== 전처리 후 ===")
print("훈련 데이터의 갯수 : %d | 테스트 데이터의 갯수 : %d"%(after_train,after_test))
#Save : 전처리한 결과를 파일로 저장해줍니다.(나중에 불러다 쓰면 편함!)
print("Save...")
train,valid = train_test_split(train_data)
train.to_csv("new_ratings_train.txt") #train data
valid.to_csv("new_ratings_valid.txt") #validation data
test_data.to_csv("new_ratings_test.txt") #test data
print("Done!")
위의 코드를 실행시키면 다음과 같이 출력이 됩니다!
#Step 2-2. 형태소 분석기 + 입력 데이터 만들기
이번 step에서는 이전에 저장한 'new_ratings_train.txt' 와 'new_ratings_test.txt'를 불러와서 사용합니다!
이제 본격적으로 형태소 분석기를 사용하여 추가 전처리를 진행하며, 모델에 input데이터로 사용할 수 있게끔 만들어 주려고 합니다.
pytorch로 데이터를 만드는 방법은 정말 여러 방법이 있습니다만
이번 포스트에서는 필드를 정의하여 사용해보려고 합니다!
참고사항!!!
만약 아래 코드를 실행했더니 data.Field 관련 에러가 발생한다면 버전차이로 인해 에러가 발생한것입니다!
그런 경우엔 다음과 같이 바꿔주세요!
(기존)
from torchtext import data
(변경 후)
from torchtext.legacy import data
################
##load_data.py##
################
import pandas as pd
from konlpy.tag import Mecab
from torchtext import data
import torch
import torchtext
'''
torchtext의 Field를 이용하여 훈련 및 테스트에 사용할 데이터를 만들어보도록 하겠습니다.
데이터를 원하는 batchsize에 나누기 전, 전처리한 데이터를 이용하여 형태소 분석을 진행합니다.
'''
#Part 1. Tokenize
#Tokenizer로 사용할 Mecab 객체를 정의합니다.(Okt등 다른 형태소 분석기를 사용해도 됩니다.)
tokenizer = Mecab()
#stopword(불용어)를 정의합니다. 사용자에 따라서 추가해서 사용할 수 있습니다.
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
#형태소 분석 후에 사용할 처리들을 모아둔 preprocess라는 이름의 함수를 정의합니다.
def preprocess(text):
#stopword를 제거합니다.
word = [t for t in text if t not in stopwords]
return word
#Part 2. Define Field
print("+"*50)
print("load data...")
print("+"*50)
#사용안할 예정
IDX = data.Field(sequential = False, use_vocab = False)
ID = data.Field(sequential= False, use_vocab = False)
#사용할 예정
TEXT = data.Field(fix_length = 20, sequential = True, batch_first = True,
is_target = False, use_vocab = True,
tokenize = tokenizer.morphs,
preprocessing = preprocess) #형태소 분석 + 형태소 분석 이후 추가 처리 진행!
LABEL = data.Field(sequential = False,batch_first = True,is_target = True,
use_vocab = False,dtype = torch.float32)
#필드 정의
field = [("idx",IDX),('id',ID),('document',TEXT),('label',LABEL)]
#이전에 처리한 문서를 불러와서 훈련에 사용할 데이터로 만들어줍니다.
train_data,valid_data,test_data = data.TabularDataset.splits(
path = '.', #반드시 있어야함!
train = 'new_ratings_train.txt',validation = "new_ratings_valid.txt", test = 'new_ratings_test.txt',#이전에 저장했던 문서!
format = 'csv',
fields = field,
skip_header = True
)
print("Done!")
print("+"*50)
print("Samples...")
print("+"*50)
for i in range(5):
print(vars(train_data[i]))
print("+"*50)
#Part 3. Make data
'''
위의 과정을 거친 data들을 batch 단위로 만들어주며,모델에 입력 할 수 있도록 Embedding 작업을 진행합니다.
Embedding은 사전 훈련된 Fasttext를 사용하며, 모델은 아래 주소에서 다운받을 수 있습니다.
https://fasttext.cc/docs/en/crawl-vectors.html
-bin파일 : fasttext 모델도 같이 들어있는 파일. + Embedding file
-text파일 : Embedding file
물론 다른 모델을 사용해도 되며, Tf-Idf를 적용해보는것도 좋습니다.
'''
vector = torchtext.vocab.Vectors(name = 'cc.ko.300.vec')
TEXT.build_vocab(train_data,vectors = vector)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
#Batch size에 맞게 데이터를 만들어줍니다.
train_batch = data.BucketIterator(
dataset = train_data,
sort = False,
batch_size = 64, #batch 크기는 64로 설정!
repeat = False,
device = device)
valid_batch = data.BucketIterator(
dataset = valid_data,
sort = False,
batch_size = 64, #batch 크기는 64로 설정!
train = False,
device = device)
test_batch = data.BucketIterator(
dataset = test_data,
sort = False,
batch_size = 64, #batch 크기는 64로 설정!
train = False,
device = device)
print("load data... Done!!")
print("+"*50)
위의 코드를 실행시키면 다음과 같이 전처리 된 데이터의 sample을 볼 수 있습니다!

#Step 3. 모델 구현하기
이제 본격적으로 모델 클래스를 정의하고 훈련을 진행해보도록 하겠습니다.
################
####model.py####
################
from load_data import *
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from tqdm import tqdm
from sklearn.metrics import accuracy_score
from torchtext.data import Iterator
class CNN_network(nn.Module):
def __init__(self,embedding_size,seq_length):
super(CNN_network,self).__init__()
#embedding layer을 정의.
'''
load_data.py에서 정의한 TEXT field를 이용하여 Embedding(Fasttext) layer를 정의해줍니다.
'''
self.seq_length = seq_length #sequence_length(이전 TEXT Field에서 정의한 fix_length값)
self.embedding_size = embedding_size
self.kernel = [2,3,4]
self.output_size = 128
#Embedding layer
self.embedding = nn.Embedding.from_pretrained(TEXT.vocab.vectors)
#Convolution layer
self.conv1 = nn.Conv1d(in_channels = self.embedding_size,out_channels =self.output_size,kernel_size = self.kernel[0],stride=1) #seq_length, out_seq,kernel_size
self.conv2 = nn.Conv1d(in_channels = self.embedding_size,out_channels =self.output_size,kernel_size = self.kernel[1],stride=1)
self.conv3 = nn.Conv1d(in_channels = self.embedding_size,out_channels =self.output_size,kernel_size = self.kernel[2],stride=1)
#pooling layer
self.pool1 = nn.MaxPool1d(self.kernel[0],stride = 1)
self.pool2 = nn.MaxPool1d(self.kernel[1],stride = 1)
self.pool3 = nn.MaxPool1d(self.kernel[2],stride = 1)
#Dropout & FC layer
self.dropout = nn.Dropout(0.25)
self.linear1 = nn.Linear(self._calculate_features(),1024)
self.linear2 = nn.Linear(1024,128)
self.linear3 = nn.Linear(128,1)
def _calculate_features(self):
'''
FC layer의 input size를 구하기 위한 함수입니다.
convolved features = ((embedding_size + (2 * padding) - dilation * (kernel - 1) -1 )/ stride ) + 1
Pooled features = ((embedding_size + (2*padding) - dilation * (kernel - 1) - 1)/stride) + 1
Source : https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html
'''
out_conv1 = (self.seq_length - 1 * (self.kernel[0] - 1)-1) + 1
out_conv1 = math.floor(out_conv1)
out_pool1 = (out_conv1 - 1 * (self.kernel[0]-1)-1 ) + 1
out_pool1 = math.floor(out_pool1)
#print(out_pool1)
out_conv2 = (self.seq_length - 1 * (self.kernel[1] - 1)-1) + 1
out_conv2 = math.floor(out_conv2)
out_pool2 = (out_conv2 - 1 * (self.kernel[1]-1)-1 ) + 1
out_pool2 = math.floor(out_pool2)
#print(out_pool2)
out_conv3 = (self.seq_length - 1 * (self.kernel[2] - 1)-1) + 1
out_conv3 = math.floor(out_conv3)
out_pool3 = (out_conv3 - 1 * (self.kernel[2]-1)-1 ) + 1
out_pool3 = math.floor(out_pool3)
#print(out_pool3)
out = (out_pool1 + out_pool2 + out_pool3) * 128 #torch.cat이후 최종 size
return out
def forward(self,input_sentence,size):
device = 'cuda' if torch.cuda.is_available() else 'cpu'
x = self.embedding(input_sentence)
x = x.transpose(1,2)
x1 = self.conv1(x)
x1 = F.sigmoid(x1)
x1 = self.pool1(x1)
x2 = self.conv2(x)
x2 = F.sigmoid(x2)
x2 = self.pool2(x2)
x3 = self.conv3(x)
x3 = F.sigmoid(x3)
x3 = self.pool3(x3)
x_concat = torch.cat((x1,x2,x3),2) #2번째 차원 기준으로 묶음.(32,30,17) + (32,30,13) => (32,30,30)
x_concat = torch.flatten(x_concat,1) #batch를 제외한 나머지를 묶어버린다 -> FC layer를 사용하기 위함. (32,30,30) -> (32,900)
out = self.linear1(x_concat)
out = self.dropout(out)
out = self.linear2(out)
out = self.dropout(out)
out = self.linear3(out)
out = F.sigmoid(out)
return out.squeeze()
위 코드는 크기가 다른 filter 3개를 이용하여 각각 Convolution 연산을 수행한 뒤, 그 결과를 합쳐서 fully-connected layer에 통과시키는 모델을 구현하였습니다.
일반적으로 1D-CNN을 이용하여 text classification을 진행할때 다음과 같이 진행합니다.
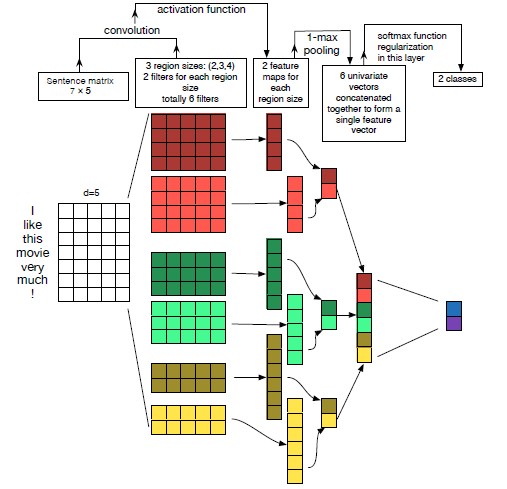
위 그림은 크기가 동일한 2개의 filter를 3개 사용하고 있지만, 저의 코드에서는 단순히 크키가 다른 filter를 1개만 사용합니다. 위 모델대로 짜려면 동일한 filter를 추가로 정의하셔서 구현해보시기 바랍니다!
#Step 4. 모델 훈련하기
이제 위에서 구현한 모델을 이용하여 훈련 및 테스트를 진행하고자 합니다.
우선 Train 함수입니다.
train 함수는 모델,train_data,valid_data를 input으로 받습니다.
여기서 train_data는 실제 모델의 훈련에 사용되며, valid_data는 한 epoch당 accuracy를 출력하는 용도로 사용하였습니다.
def train(model,train_data,valid_data):
device = 'cuda' if torch.cuda.is_available() else 'cpu'
#훈련 모드 ON
model.train()
#optimizer 정의
optimizer = optim.AdamW(model.parameters(),lr = 0.0001)
#loss
loss_fn = torch.nn.BCELoss()
epochs = 10
for epoch in range(epochs):
t_loss = 0
for batch_idx,batch in tqdm(enumerate(train_data)):
text = batch.document
label = batch.label
label = torch.tensor(label,dtype=torch.float,device = device)
size = len(text)
out = model(text,size)
loss = loss_fn(out,label)
#update parameters
optimizer.zero_grad()
loss.backward()
optimizer.step()
t_loss += loss.detach().item()
print(f"Epoch : {epoch + 1} / {epochs} \t Train Loss : {t_loss/len(train_data) : .3f}")
test(model,valid_data)#Step 5. 모델 테스트하기
다음은 test함수입니다.
test함수는 입력된 데이터에 대해 모델이 예측을 진행하며, 그 결과를 Accuracy로 표현해줍니다.
함수 자체는 간단하게 만들어보았습니다..ㅎㅎ
def test(model,data):
#평가 모드로 진입
model.eval()
#prediction
predictions = []
labels = []
with torch.no_grad():
for batch in data:
text = batch.document
label = batch.label
size = len(text)
y_pred = model(text,size)
for i in y_pred:
if i >= 0.5:
predictions.append(1)
else:
predictions.append(0)
for j in label:
labels.append(j.cpu())
print(f"Accuracy : {accuracy_score(labels,predictions) : .3f}")
print("sample pred : ",predictions[:10])
print('sample labels : ',labels[:10])
print("="*100)#Step 6. 유저가 입력한 문장 판단하기
마지막으로 유저가 직접!! 문장을 입력하면 모델이 긍/부정을 예측해주는 predict 함수를 만들어보았습니다.
test 데이터에 있는 데이터의 긍/부정을 모델이 판단하기는 하지만 본인이 직접 작성한 리뷰를 모델이 어떻게 판단하는지 궁금하지 않으신가요?ㅎㅎ
def predict(model,sentence):
model.eval()
with torch.no_grad():
sent = tokenizer.morphs(sentence)
sent = torch.tensor([TEXT.vocab.stoi[i] for i in sent])
sent = F.pad(sent,pad = (1,20-len(sent)-1),value = 1)
sent = sent.unsqueeze(dim = 0) #for batch
output = model(sent,len(sent))
return output.item()#Step 6-1. 실행 및 결과 확인하기
자 이제 필요한 모든 함수 및 클래스는 구현이 끝이 났습니다.
이제 직접 실행시켜서 확인해봅시다!
if __name__ == "__main__":
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = CNN_network(embedding_size=300,seq_length=20).to(device)
#train
train(model,train_batch,valid_batch)
#test
print("===TEST===")
test(model,test_batch)
#사용자가 입력한 문장에 대해 긍/부정 판단(0을 입력하면 종료)
while True:
user = input("테스트 할 리뷰를 작성하세요 : ")
if user == '0':
break
model = model.to('cpu')
pred = predict(model,user)
if pred >= 0.5 :
print(f">>>긍정 리뷰입니다. ({pred : .2f})")
else:
print(f">>>부정 리뷰입니다.({pred : .2f})")
위의 코드를 실행시키면 다음과 같이 훈련이 잘 되는것을 보실 수 있습니다.
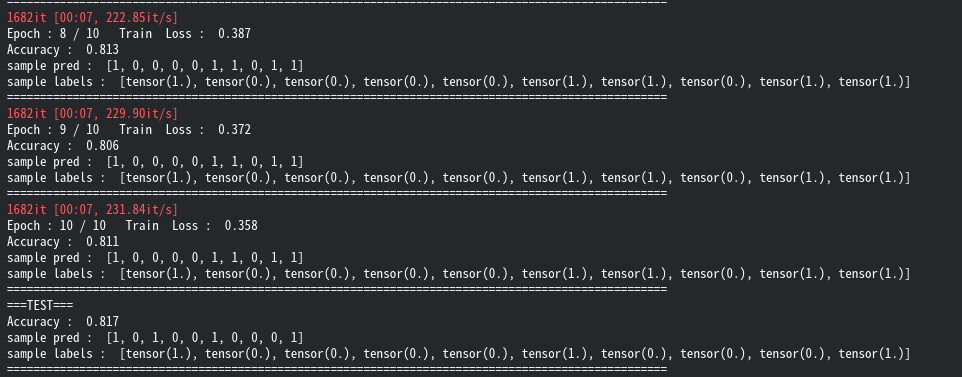
제가 학습을 진행해보았을땐 테스트 데이터의 최고 Accuracy는 0.82가 나왔으며, 최저는 0.78이였습니다.
제 코드를 이용하시는분들은 layer를 추가하거나 filter를 추가하는 방식 등 여러 방법을 이용하여 저보다 Accuracy가 높게 나오셨으면 좋겠습니다ㅎㅎ
마지막으로 제가 직접 입력한 문장에 대해 CNN모델이 긍/부정을 판단하는 모습도 잘 동작함을 볼 수 있었습니다.
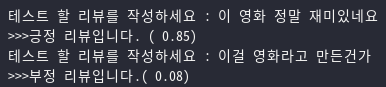
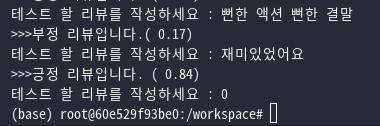
일반적으로 CNN은 MNIST 같이 이미지 데이터를 분류할때 많이 사용하는 모델이지만, 이렇게 문장 분류도 어느정도 좋은 성능을 낸다는것을 확인 할 수 있었습니다.
긴 글 읽어주셔서 감사합니다.
오류 및 질문은 댓글 남겨주시면 답변 드리겠습니다!
[참고 사이트]
[1] https://wikidocs.net/44249
[2] https://ichi.pro/ko/pytorcheseo-cnneul-sayonghan-tegseuteu-bunlyu-18777046640543
'자연어 처리(NLP) > 모델(Model)' 카테고리의 다른 글
| RNN/LSTM/GRU 의 구조를 이해해보자 (0) | 2022.11.08 |
|---|---|
| Transformer를 이용한 번역모델 구축 (4) | 2022.01.22 |
| Transformer를 이해하고 구현해보자! (2) (0) | 2022.01.21 |
| Transformer를 이해하고 구현해보자! (1) (7) | 2021.10.25 |
| CNN(Convolutional Neural Network) 이해하기 (0) | 2020.02.05 |



